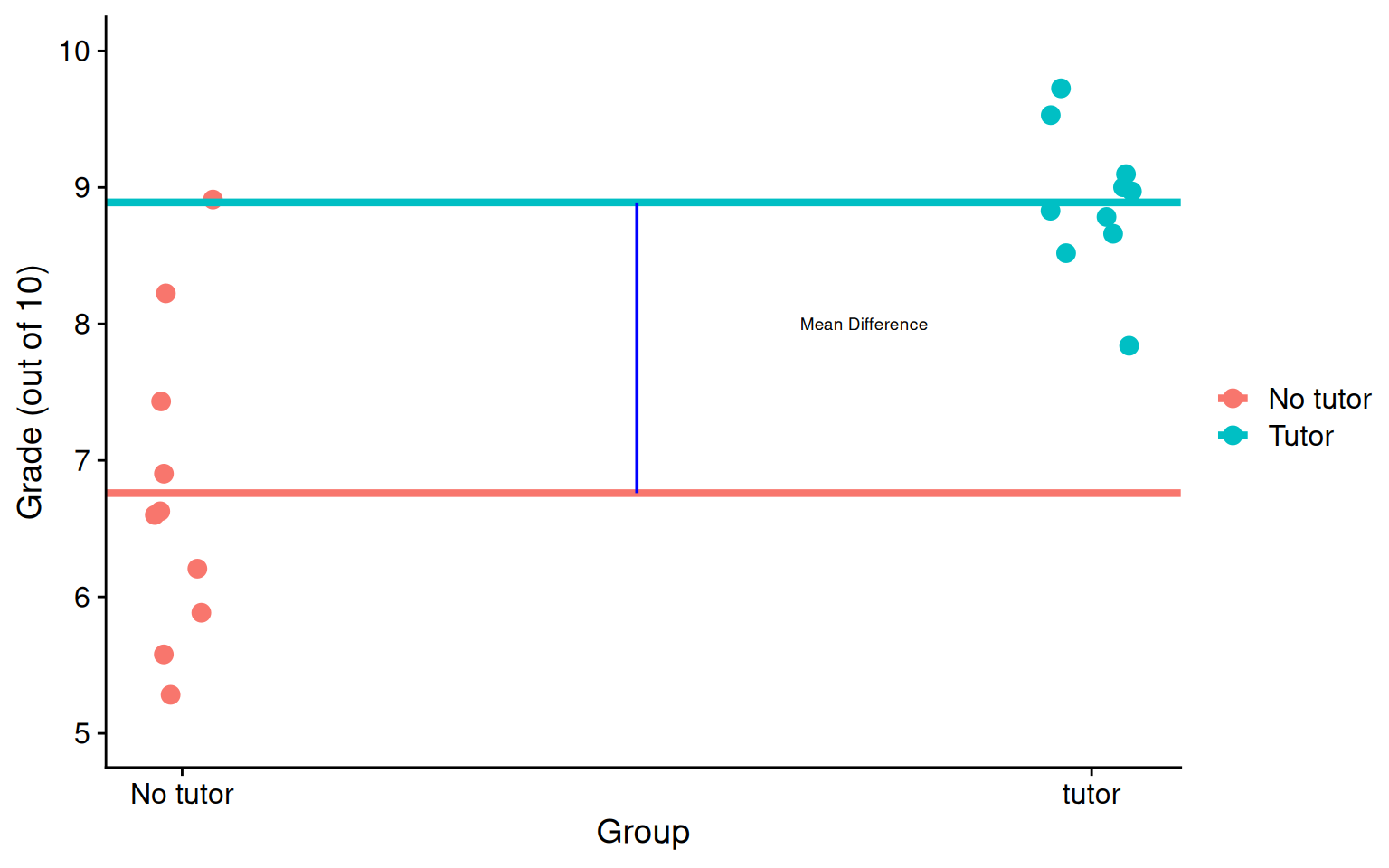
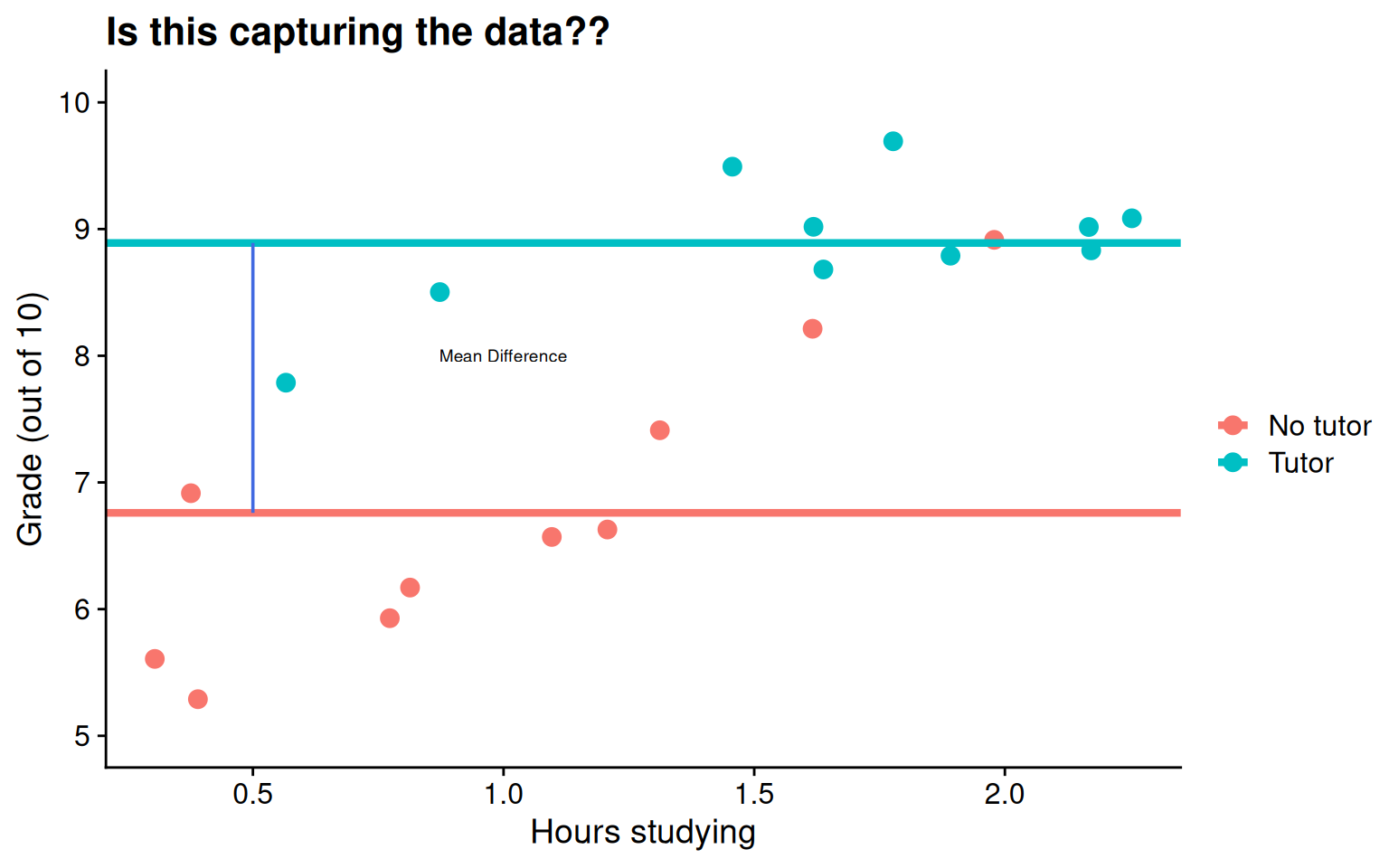
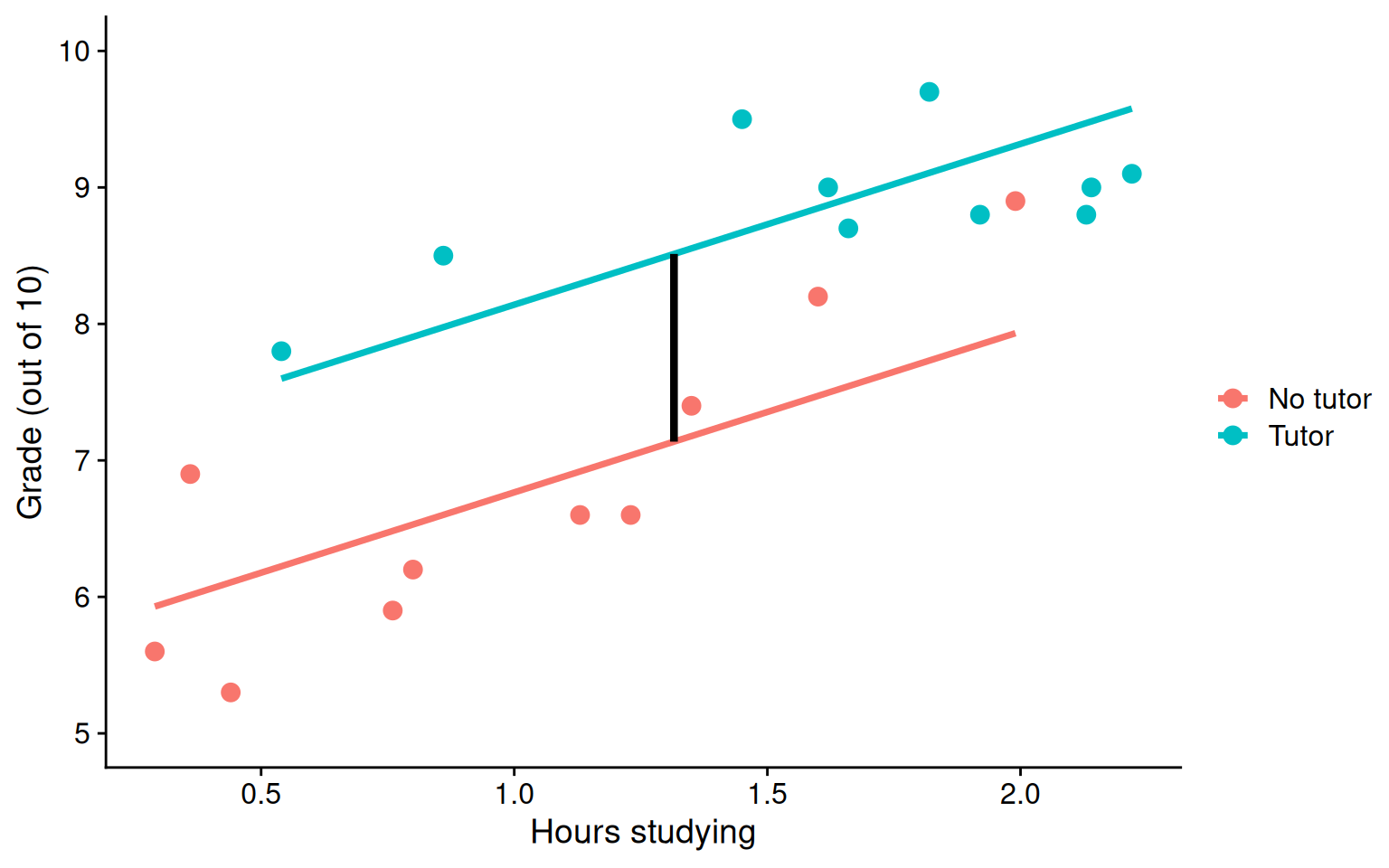
\(b_0\) is the mean of the reference group (no tutor), and \(b_1\) represents the difference in means between the two groups.
Visualizing
Code
means <- t_data %>%group_by(tutor_lab) %>%summarize(M =mean(grade))no_tutor <-as.numeric(means[1,2])tutor <-as.numeric(means[2,2])t_data %>%ggplot(aes(tutor, grade, color = tutor_lab)) +geom_jitter(size =3, width = .05) +geom_hline(aes(yintercept = M, color = tutor_lab), data = means, linewidth =1.5) +annotate("segment", x =0.5, xend =0.5, y = no_tutor, yend = tutor,colour ="blue") +annotate("text", x = .75, y =8, label ="Mean Difference", size =2.5) +scale_x_continuous(breaks =c(0,1), labels =c("No tutor", "tutor")) +scale_y_continuous(limits =c(5,10)) +labs(x ="Group", y ="Grade (out of 10)", color ="") + cowplot::theme_cowplot()
Visualizing
Code
means <- t_data %>%group_by(tutor_lab) %>%summarize(M =mean(grade))no_tutor <-as.numeric(means[1,2])tutor <-as.numeric(means[2,2])t_data %>%ggplot(aes(study, grade, color = tutor_lab)) +geom_jitter(size =3, width = .05) +geom_hline(aes(yintercept = M, color = tutor_lab), data = means, linewidth =1.5) +annotate("segment", x =0.5, xend =0.5, y = no_tutor, yend = tutor,colour ="royalblue") +annotate("text", x =1, y =8, label ="Mean Difference", size =2.5) +labs(x ="Hours studying", y ="Grade (out of 10)", color ="", title ="Is this capturing the data??") +scale_y_continuous(limits =c(5,10)) + cowplot::theme_cowplot()
Interpreting slopes
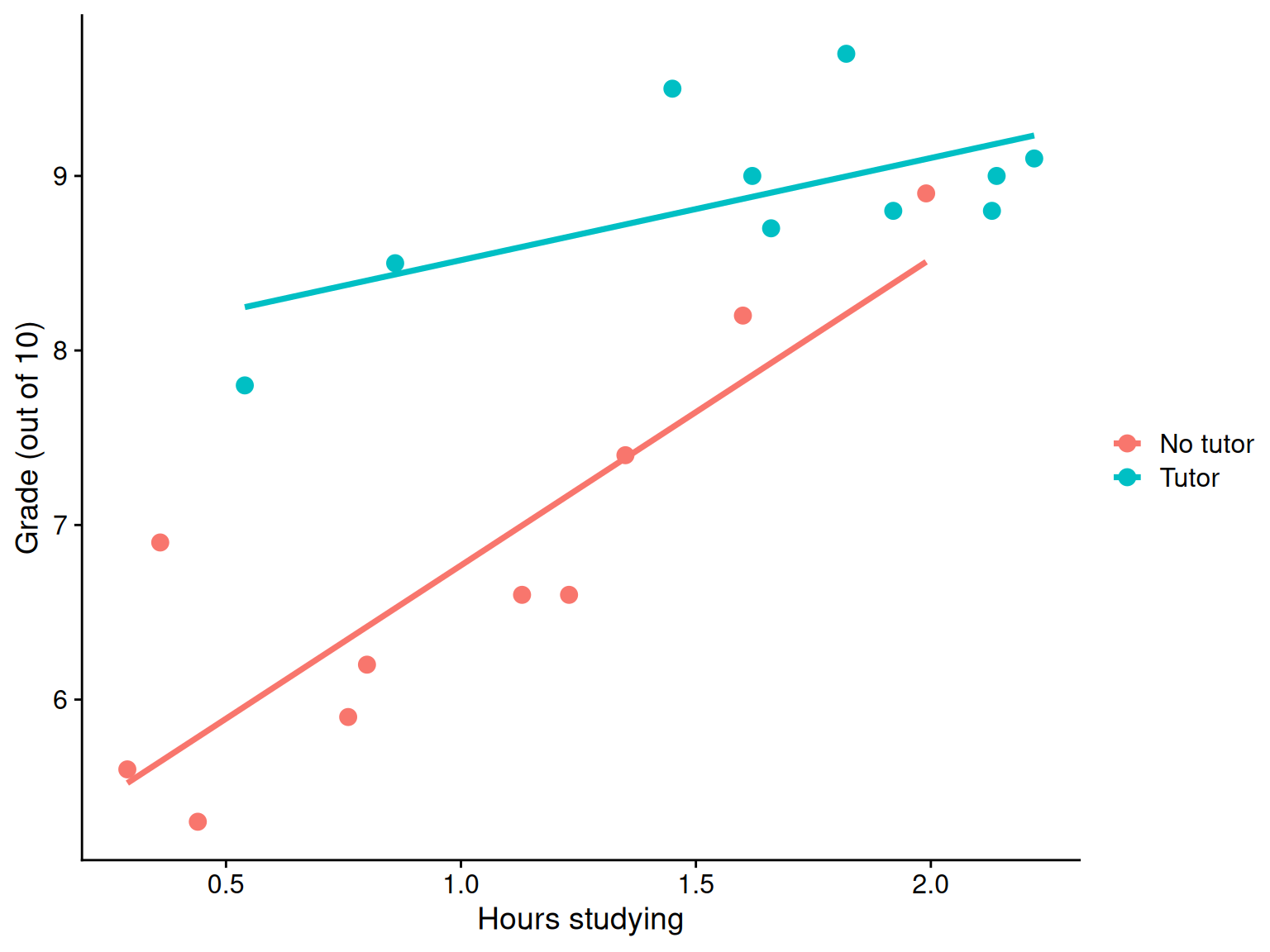
Extending this to the multivariate case, let’s add hours spent studying (study) as another covariate.
mod2 <-lm(grade ~ tutor_lab + study, data = t_data)summary(mod2)
...
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 5.5882 0.3198 17.474 0.00000000000269 ***
tutor_labTutor 1.3751 0.3183 4.320 0.000465 ***
study 1.1777 0.2565 4.592 0.000259 ***
...
\(b_1\) is the difference in means between the two groups if the two groups have the same average level of hours studying or holding study constant.
BTW this is an ANCOVA.
Visualizing
Code
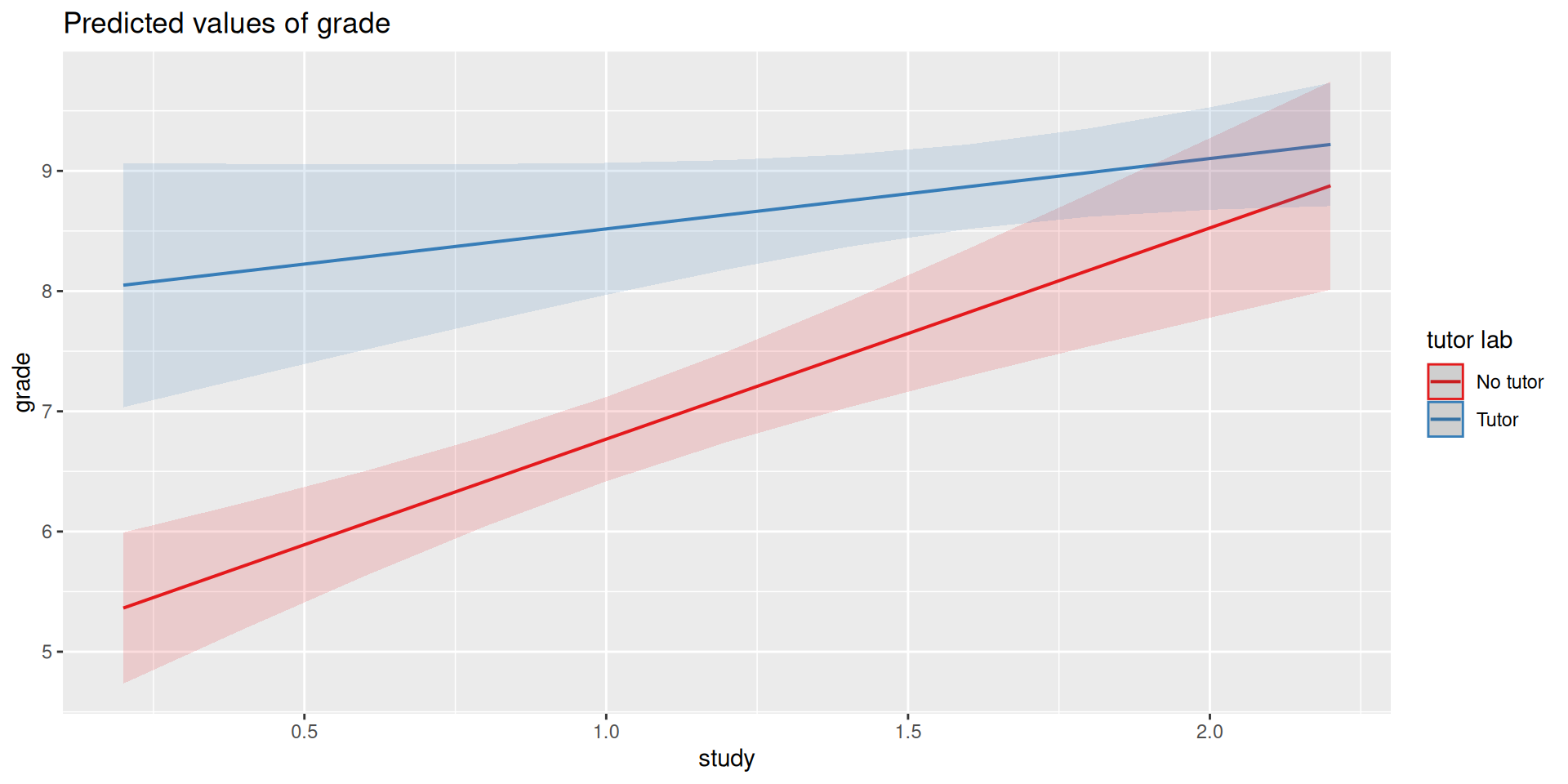
mod =lm(grade ~ study + tutor_lab, data = t_data)t_data$pmod =predict(mod)predict.2=data.frame(study =rep(mean(t_data$study), 2), tutor_lab =c("No tutor", "Tutor"))predict.2$grade =predict(mod, newdata = predict.2) predict.2=cbind(predict.2[1,], predict.2[2,])names(predict.2) =c("x1", "d1", "y1", "x2", "d2", "y2")ggplot(t_data, aes(study,grade, color = tutor_lab)) +geom_point(size =3, aes(color = tutor_lab)) +geom_smooth(aes(y = pmod), method ="lm", se = F)+geom_segment(aes(x = x1, y = y1, xend = x2, yend = y2), data = predict.2, inherit.aes = F, size =1.5)+labs(x ="Hours studying", y ="Grade (out of 10)", color ="") +scale_y_continuous(limits =c(5,10)) + cowplot::theme_cowplot()
Visualizing
Code
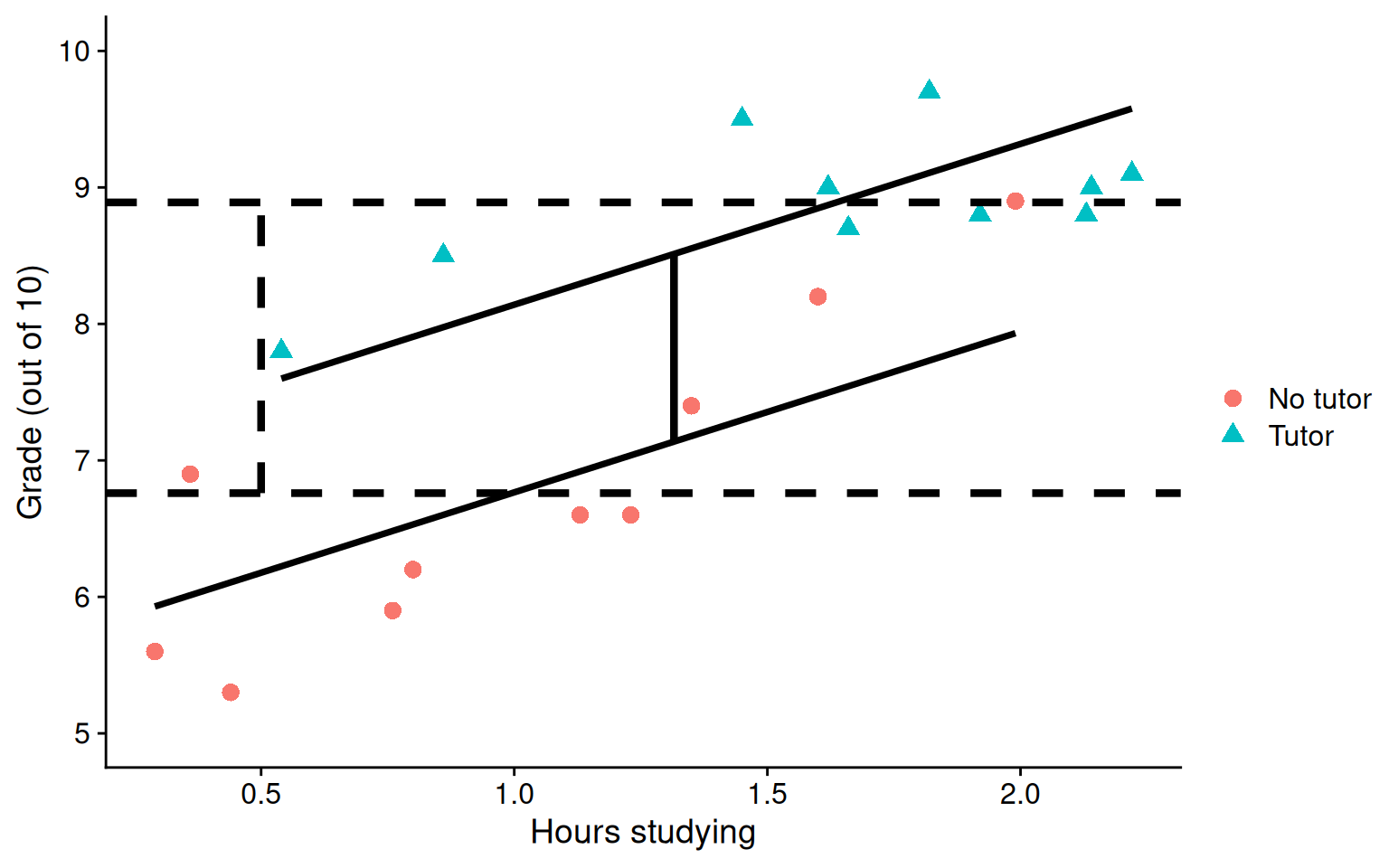
ggplot(t_data, aes(study, grade, group = tutor_lab)) +geom_point(size =3, aes(shape = tutor_lab, color = tutor_lab)) +geom_smooth(aes(y = pmod), method ="lm", se = F, color ="black")+geom_hline(aes(yintercept = M), linetype ="dashed",data = means, size =1.5) +geom_segment(aes(x = x1, y = y1, xend = x2, yend = y2), data = predict.2, inherit.aes = F, size =1.5) +annotate("segment", x =0.5, xend =0.5, y = no_tutor, yend = tutor,linetype ="dashed", linewidth =1.5) +labs(x ="Hours studying", y ="Grade (out of 10)", color ="", shape ="") +scale_y_continuous(limits =c(5,10)) + cowplot::theme_cowplot()
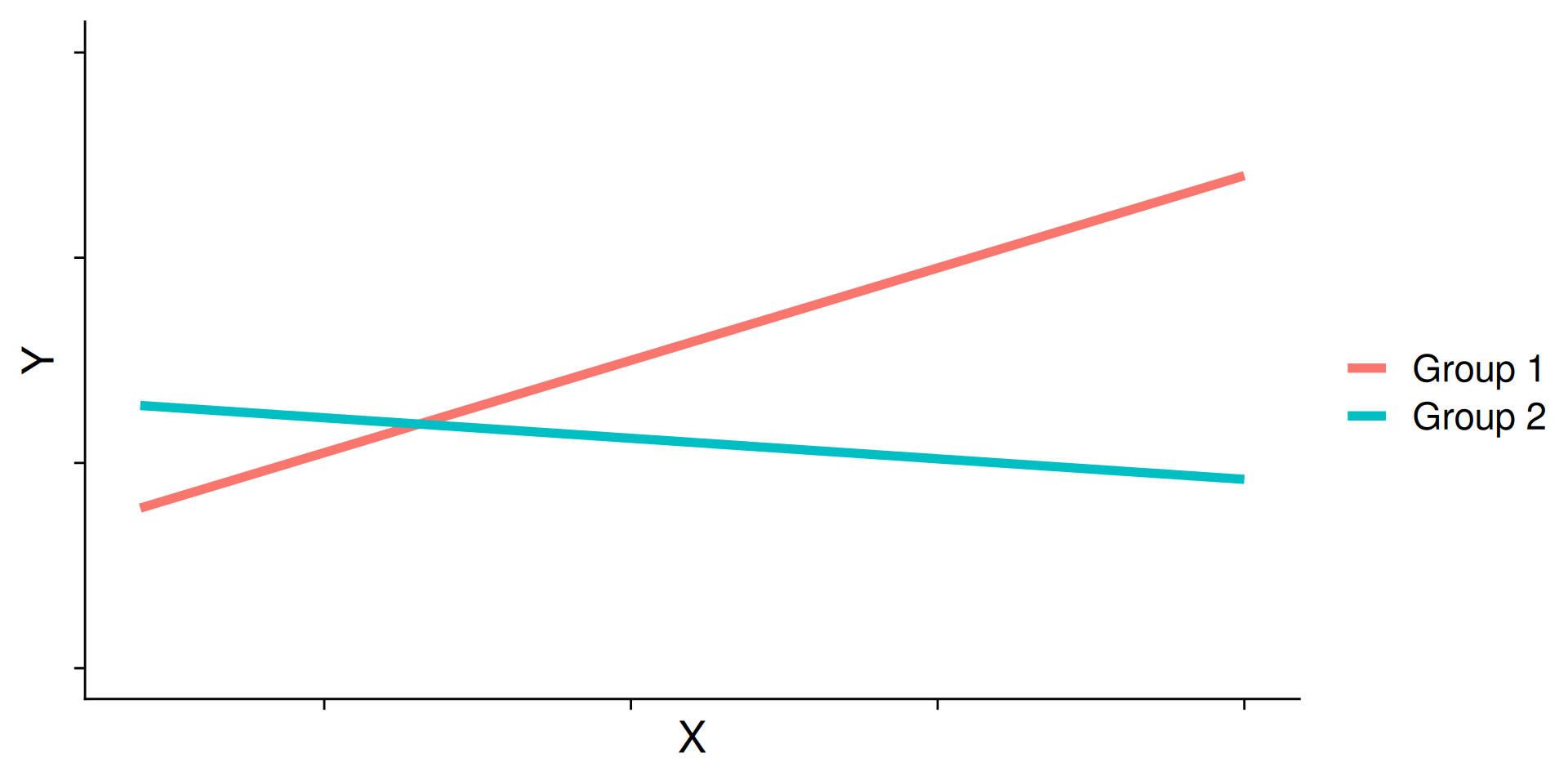
What are interactions?
When we have two variables, A and B, in a regression model, we are testing whether these variables have additive effects on our outcome, Y. That is, the effect of A on Y is constant over all values of B.
Example: Studying and working with a tutor have additive effects on grades; no matter how many hours I spend studying, working with a tutor will improve my grade by 2 points.
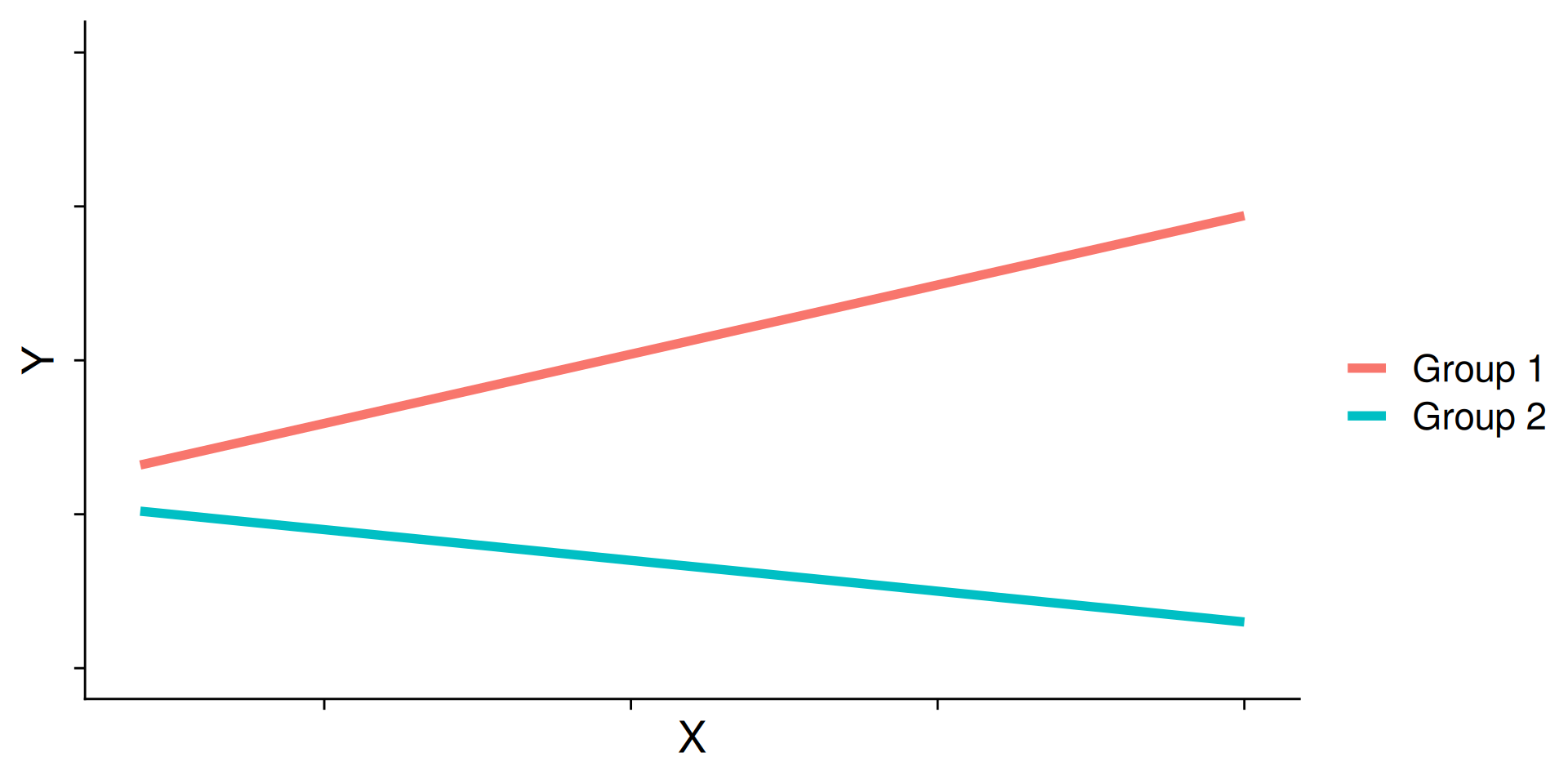
What are interactions?
However, we may hypothesis that two variables have joint effects, or interact with each other. In this case, the effect of A on Y changes as a function of B.
Example: Working with a tutor has a positive impact on grades but only for individuals who do not spend a lot of time studying; for individuals who study a lot, tutoring will have little or no impact.
This is also referred to as moderation.
Interactions (moderation) tell us whether the effect of one IV (on a DV) depends on another IV.
Interactions
Now extend this example to include joint effects, not just additive effects:
ggplot(t_data, aes(study, grade, color = tutor_lab)) +geom_point(size =3) +geom_smooth(method ="lm", se = F)+labs(x ="Hours studying", y ="Grade (out of 10)", color ="") + cowplot::theme_cowplot()
Where should we draw the segment to compare means?
the linear effect of the product of hours studying and tutoring
how much the slope of study differs for the two tutoring groups
how much the effect of tutoring changes for for every one 1 hour increase in studying.
Terms
Interactions tell us whether the effect of one IV (on a DV) depends on another IV. In this case, the effect of tutoring depends on a student’s time spent studying. Tutoring has a large effect when a student’s spends little time studying, but a small effect when the amount of time studying is high.
\(b_3\) is referred to as a “higher-order term.”
Higher-order terms are those terms that represent interactions.
Terms
Lower-order terms change depending on the values of the higher-order terms. The value of \(b_1\) and \(b_2\) will change depending on the value of \(b_3\).
These values represent “conditional effects” (because the value is conditional on the level of the other variable). In many cases, the value and significance test with these terms is either meaningless (if an IV is never equal to 0) or unhelpful, as these values and significance change across the data.
Conditional effects and simple slopes
The regression line estimated in this model is quite difficult to interpret on its own. A good strategy is to decompose the regression equation into simple slopes, which are determined by calculating the conditional effects at a specific level of the moderating variable.
Simple slope: the equation for Y on X at different levels of Z
Conditional effect: the slope coefficients in the full regression model that can change. These are the lower-order terms associated with a variable. E.g., studying has a conditional effect on grade.
The conditional nature of these effects is easiest to see by “plugging in” different values for one of your variables. Return to the regression equation estimated in our tutoring data:
Often we graph the simple slopes as a way to understand the interaction. The shape of the lines in the graph are informative and help us interpret conceptually what’s happening.
Cross-over interactions
Ordinal interactions
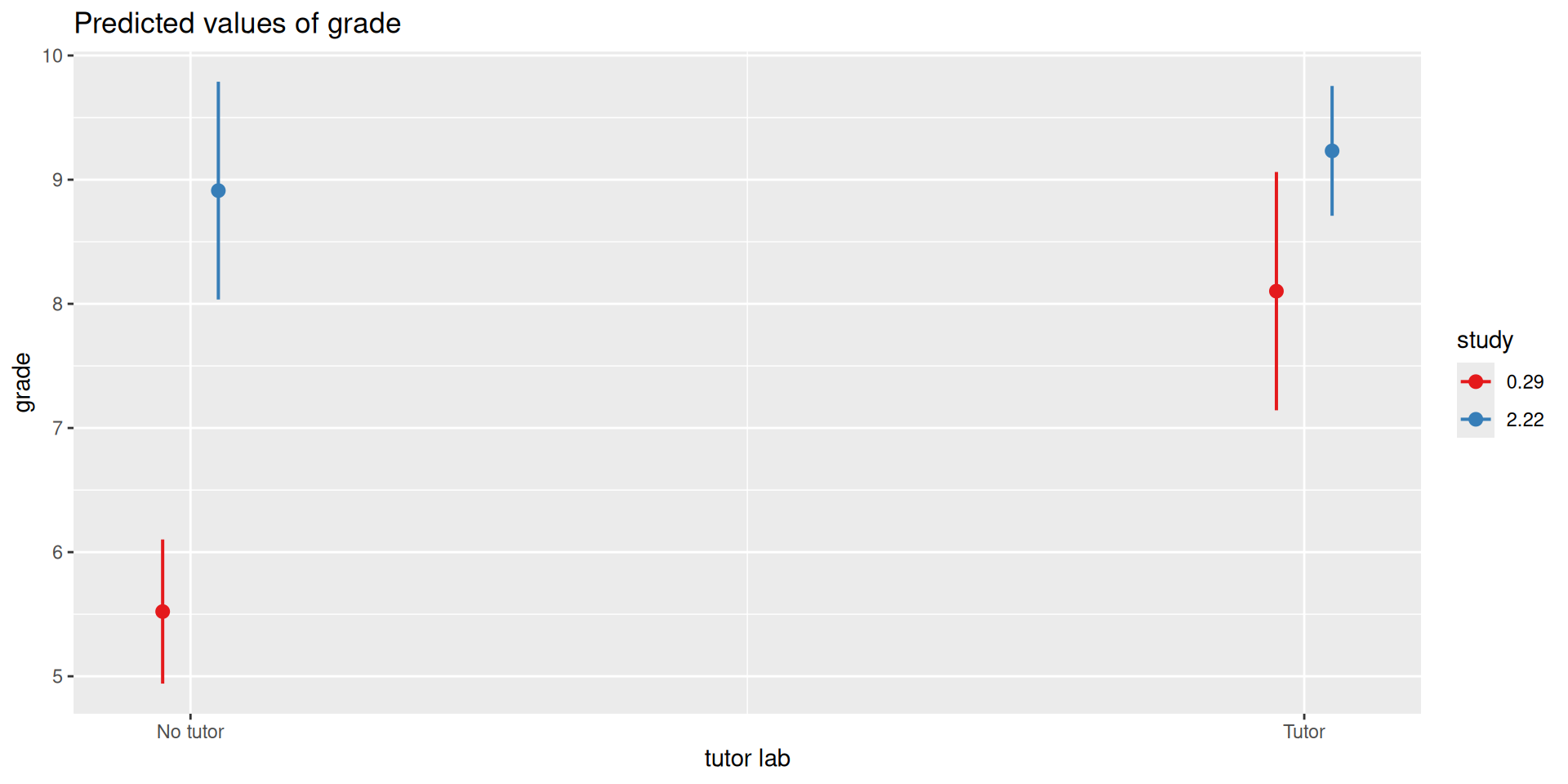
library(sjPlot)plot_model(mod3, type ="int")
library(sjPlot)plot_model(mod3, type ="pred", terms =c("study", "tutor_lab"))
Centering
The regression equation built using the raw data is not only difficult to interpret, but often the terms displayed are not relevant to the hypotheses we’re interested.
\(b_0\) is the expected value when all predictors are 0, but this may never happen in real life
\(b_1\) is the effect of tutoring when hours spent studying is equal to 0, but this may not ever happen either.
Centering your variables by subtracting the mean from all values can improve the interpretation of your results.
Remember, a linear transformation does not change associations (correlations) between variables. In this case, it only changes the interpretation for some coefficients.
t_data = t_data %>%mutate(study_c = study -mean(study))head(t_data)
summary(lm(grade ~ tutor_lab + study_c + tutor_lab:study_c, data = t_data))
Call:
lm(formula = grade ~ tutor_lab + study_c + tutor_lab:study_c,
data = t_data)
Residuals:
Min 1Q Median 3Q Max
-0.5728 -0.3837 -0.1584 0.1838 1.2555
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 7.3230 0.1929 37.963 < 0.0000000000000002 ***
tutor_labTutor 1.3794 0.2732 5.049 0.000119 ***
study_c 1.7567 0.3095 5.676 0.0000344 ***
tutor_labTutor:study_c -1.1713 0.4402 -2.661 0.017093 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.5232 on 16 degrees of freedom
Multiple R-squared: 0.8811, Adjusted R-squared: 0.8588
F-statistic: 39.53 on 3 and 16 DF, p-value: 0.0000001259
summary(mod3)
Call:
lm(formula = grade ~ tutor_lab + study + tutor_lab:study, data = t_data)
Residuals:
Min 1Q Median 3Q Max
-0.5728 -0.3837 -0.1584 0.1838 1.2555
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 5.0121 0.3496 14.337 0.00000000015 ***
tutor_labTutor 2.9203 0.6418 4.550 0.000328 ***
study 1.7567 0.3095 5.676 0.00003443132 ***
tutor_labTutor:study -1.1713 0.4402 -2.661 0.017093 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.5232 on 16 degrees of freedom
Multiple R-squared: 0.8811, Adjusted R-squared: 0.8588
F-statistic: 39.53 on 3 and 16 DF, p-value: 0.0000001259
What changed? What stayed the same?
Wrapping Up
We just examined moderation as an interaction between a categorical variable and a continuous variable
Next Steps
Moderations with two continuous predictors
What are interactions?
When we have two variables, A and B, in a regression model, we are testing whether these variables have additive effects on our outcome, Y. That is, the effect of A on Y is constant over all values of B.
Example: Drinking coffee and hours of sleep have additive effects on alertness; no matter how any hours I slept the previous night, drinking one cup of coffee will make me .5 SD more awake than not drinking coffee.
What are interactions?
However, we may hypothesis that two variables have joint effects, or interact with each other. In this case, the effect of A on Y changes as a function of B.
Example: Chronic stress has a negative impact on health but only for individuals who receive little or no social support; for individuals with high social support, chronic stress has no impact on health.
This is also referred to as moderation.
The “interaction term” is the regression coefficient that tests this hypothesis.
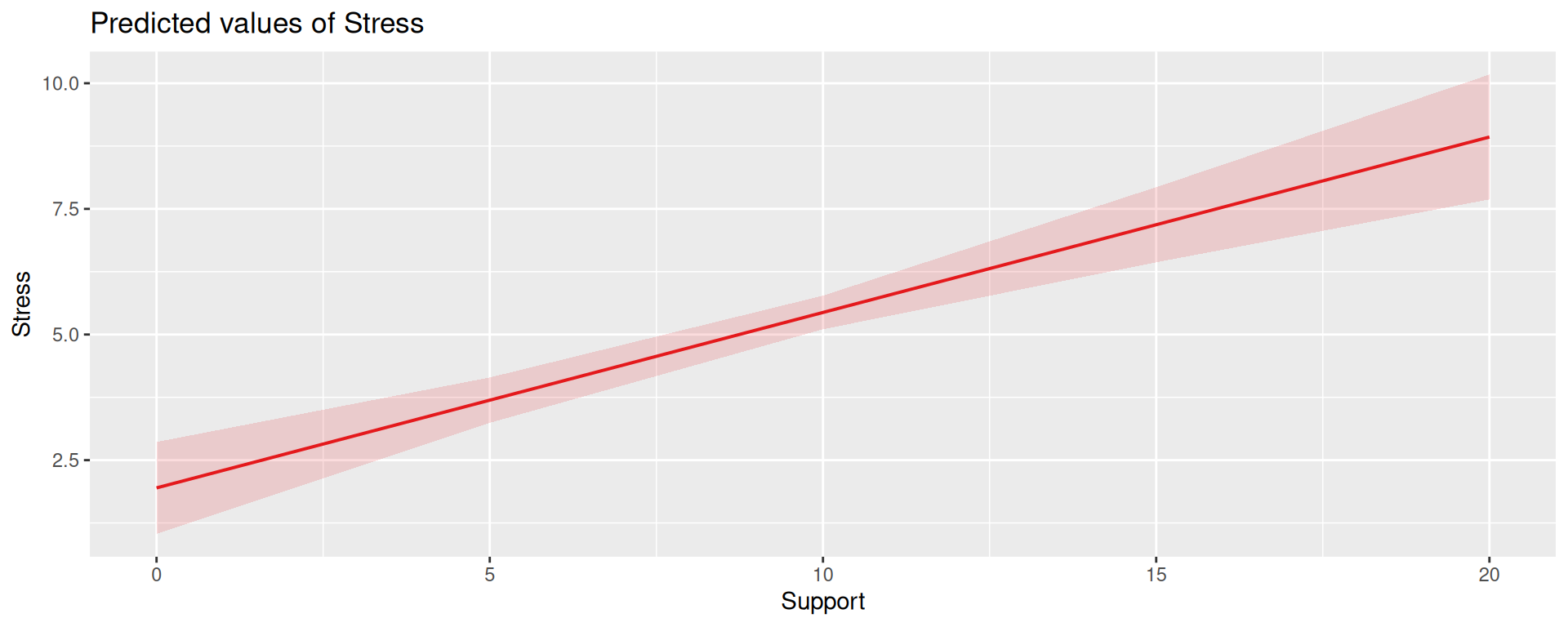
Univariate regression
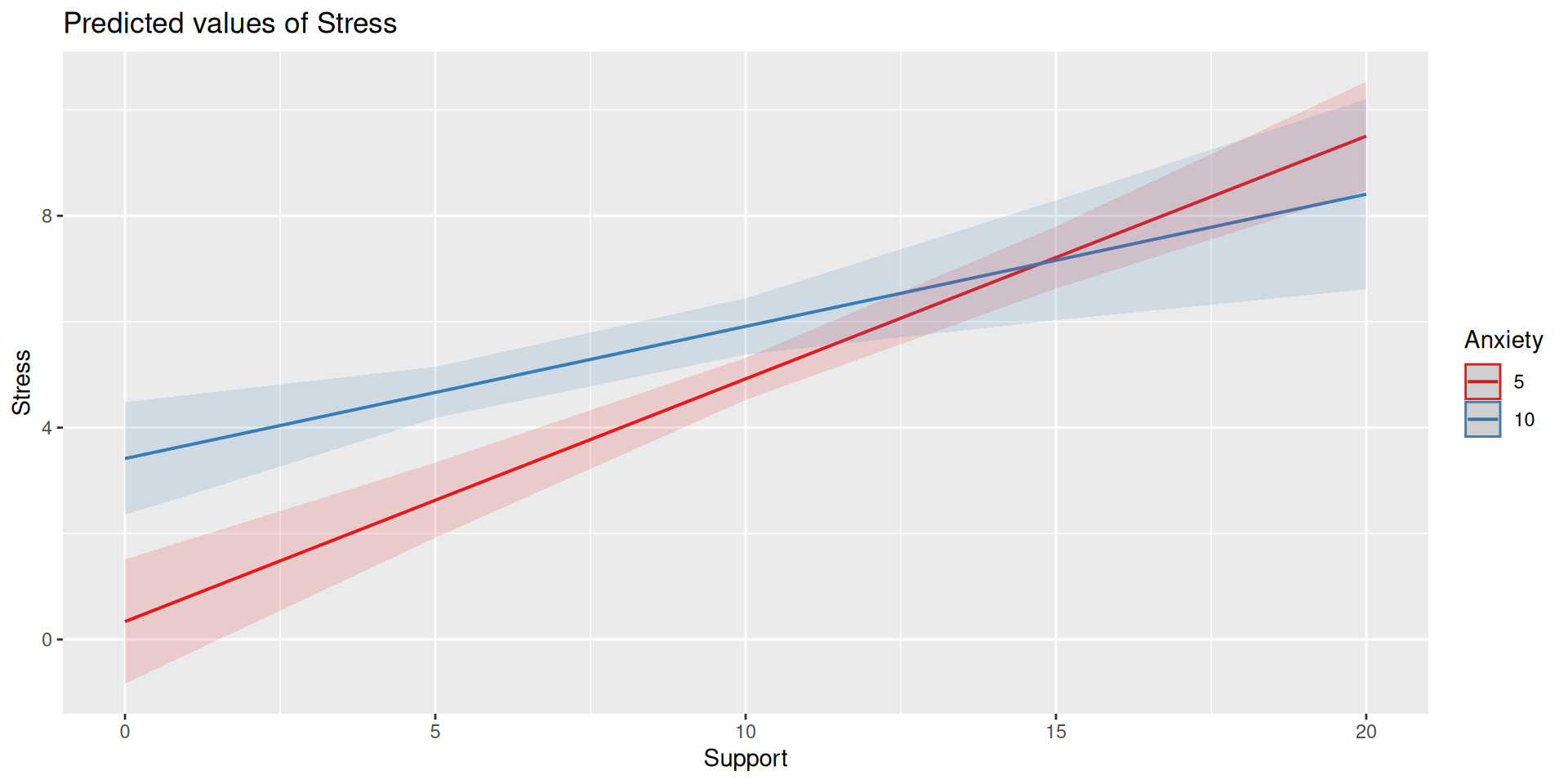
Multivariate regression
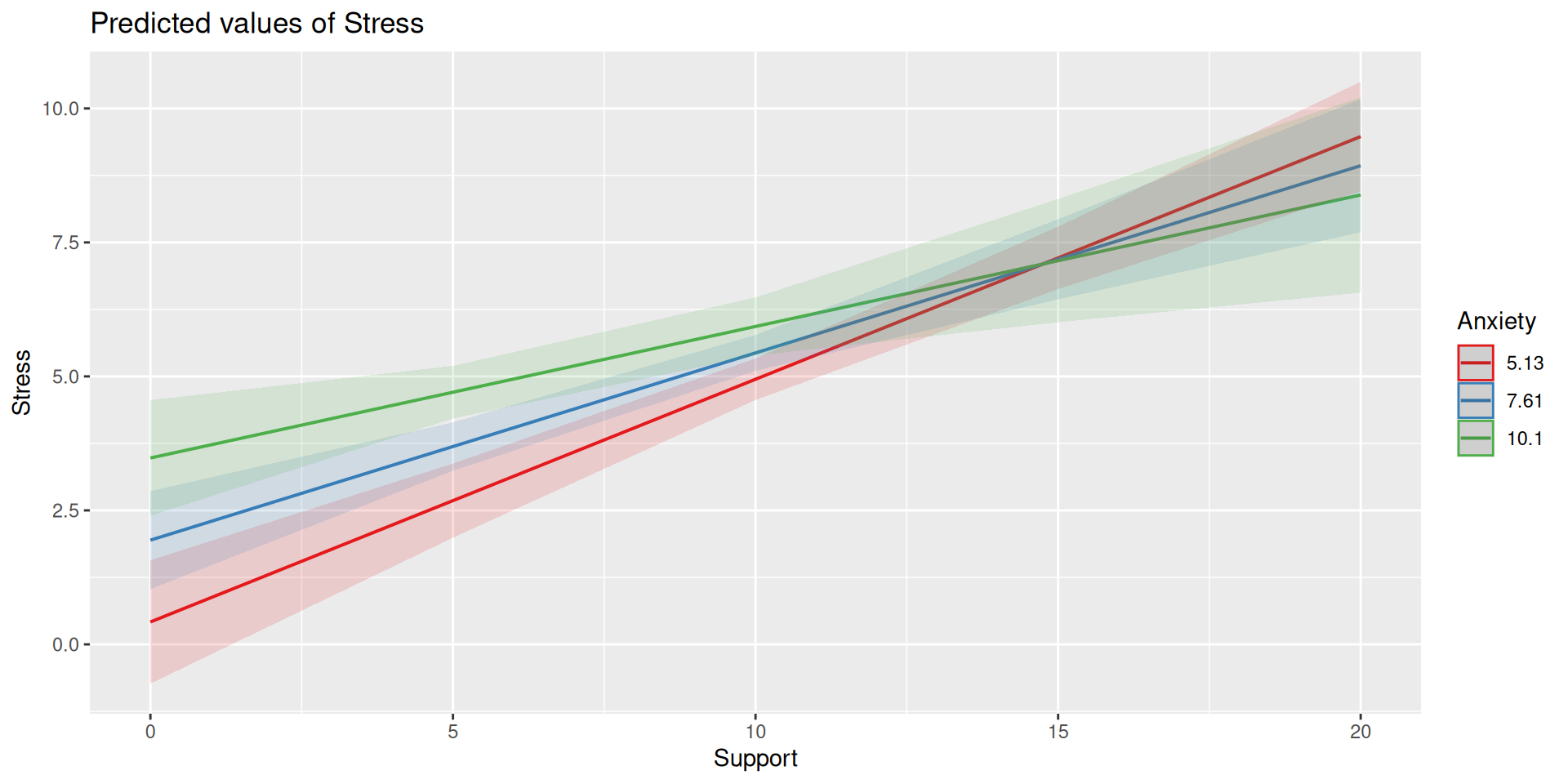
Multivariate regression with an interaction
Example
Here we have an outcome (Stress) that we are interested in predicting from trait Anxiety and levels of social Support.
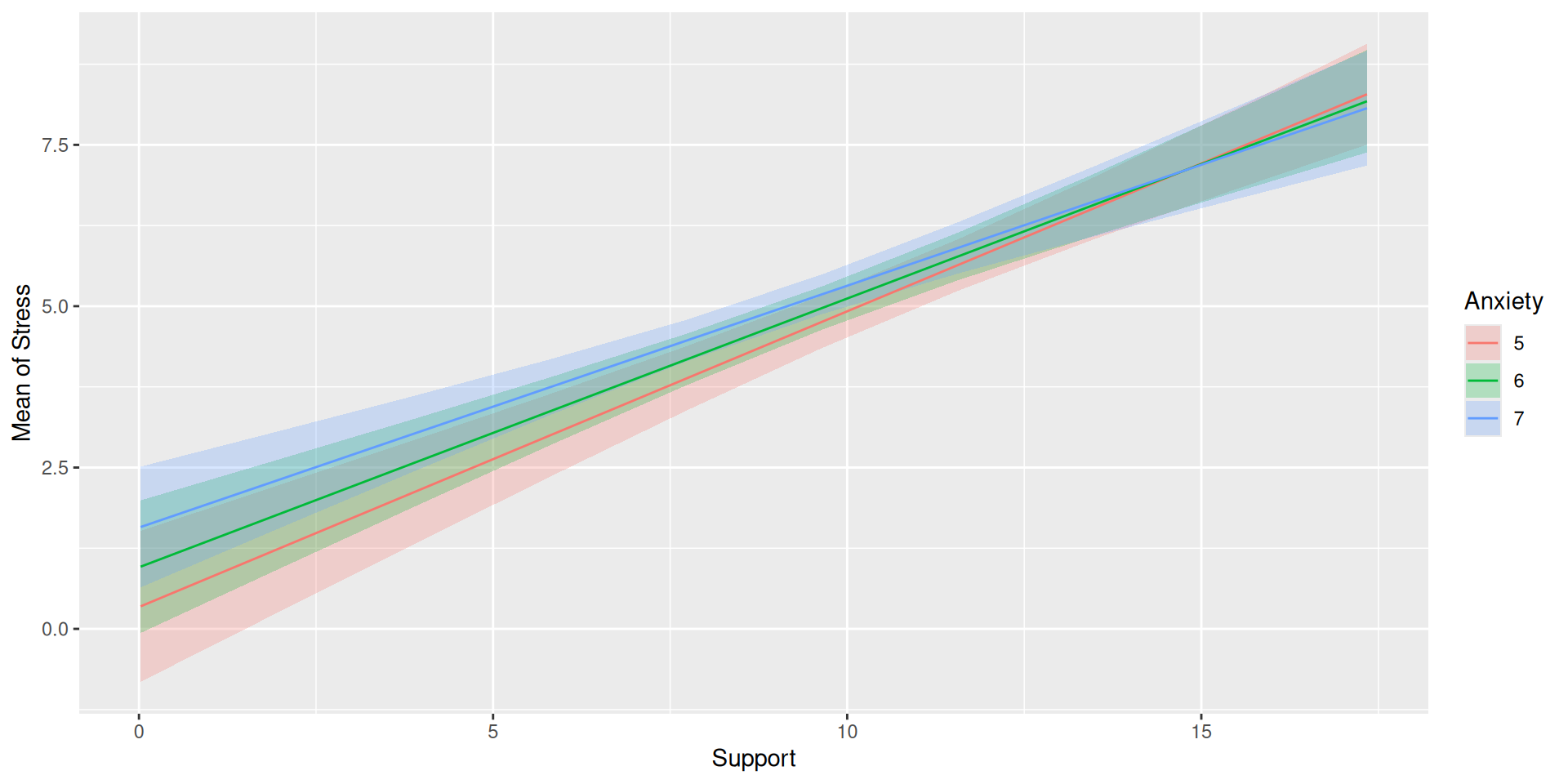
The regression line estimated in this model is quite difficult to interpret on its own. A good strategy is to decompose the regression equation into simple slopes, which are determined by calculating the conditional effects at a specific level of the moderating variable.
Simple slope: the equation for Y on X at different levels of Z; but also refers to only the coefficient for X in this equation
Conditional effect: the slope coefficients in the full regression model which can change. These are the lower-order terms associated with a variable.
The conditional nature of these effects is easiest to see by “plugging in” different values for one of your variables. Return to the regression equation estimated in our stress data:
The conditional nature of these effects is easiest to see by “plugging in” different values for one of your variables. Return to the regression equation estimated in our stress data:
The conditional nature of these effects is easiest to see by “plugging in” different values for one of your variables. Return to the regression equation estimated in our stress data:
Perhaps you noted that the t-statistic and p-values are the same… The OLS model constrains the change in slope to be equal equivalent across values of the moderator.
Remember, regression and ANOVA are mathematically equivalent – both divide the total variability in \(Y\) into variability overlapping with (“explained by”) the model and residual variability.
What differs is the way results are presented. The regression framework is excellent for continuous variables, but interpreting the interactions of categorical variables is more difficult.