Wk 5 - Hypothesis & Power
PSYC 640 - Fall 2023
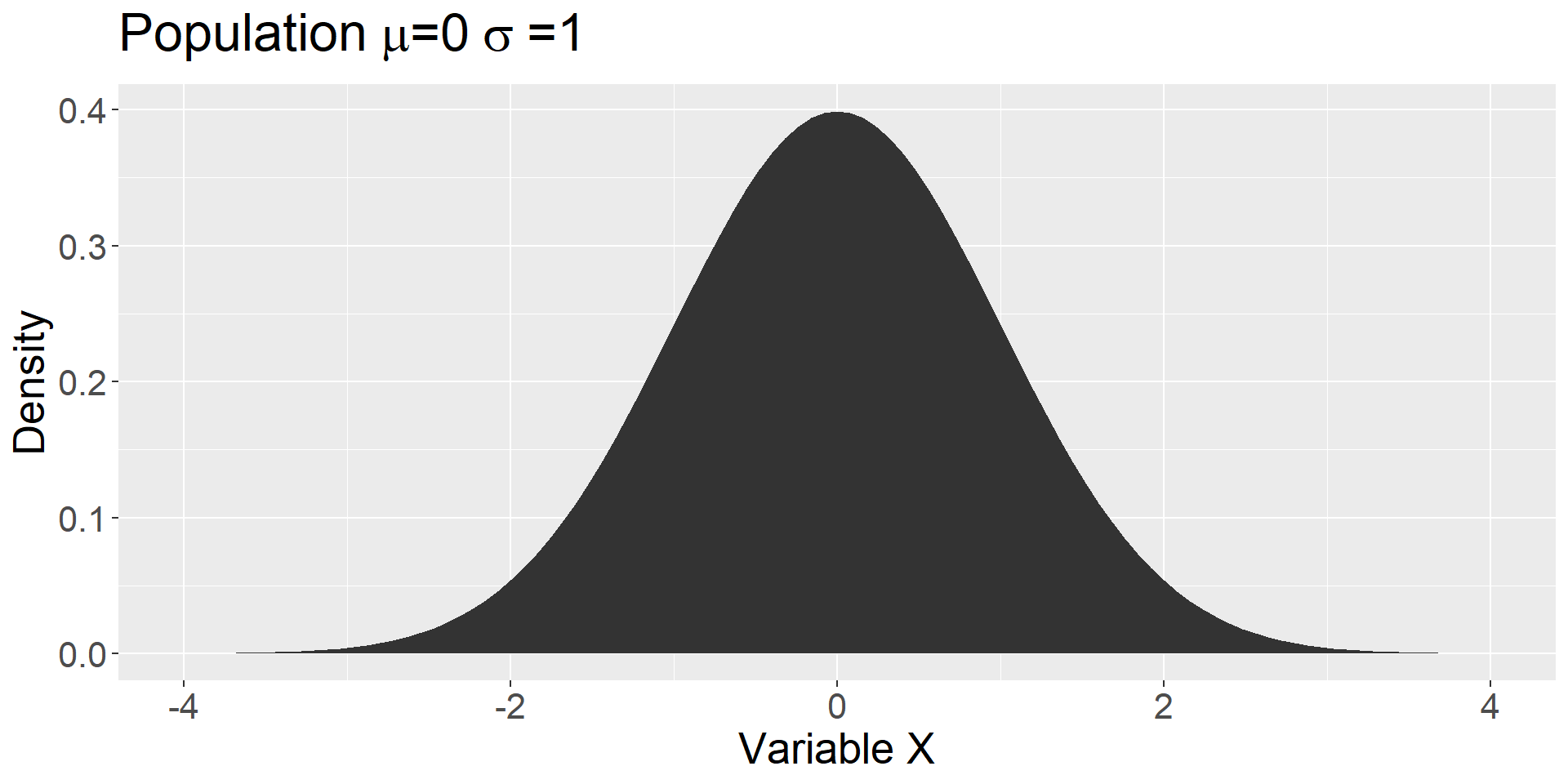
Population distribution
The parameters of this distribution are unknown. We use the sample to inform us about the likely characteristics of the population.
Samples from the population.
Each sample distribution will resemble the population. That resemblance will be better as sample size increases: The Law of Large Numbers.
Statistics (e.g., mean) can be calculated for any sample.
Code
library(ggpubr) #for multiple plots
sample_size = 30
set.seed(101919)
for(i in 1:4){
sample = rnorm(n = sample_size)
m = round(mean(sample),3)
s = round(sd(sample),2)
p = data.frame(x = sample) %>%
ggplot(aes(x = x)) +
geom_histogram(color = "white") +
geom_vline(aes(xintercept = mean(x)),
color = "purple", size = 2, alpha = .5)+
scale_x_continuous(limits = c(-4,4)) +
scale_y_continuous("", breaks = NULL) +
labs(title = as.expression(bquote("Sample"~.(i)~", m ="~.(m)~", sd ="~.(s))))
assign(paste0("p",i), p) +
theme(text = element_text(size = 20))
}
ggarrange(p1,p2,p3,p4, ncol =2, nrow = 2)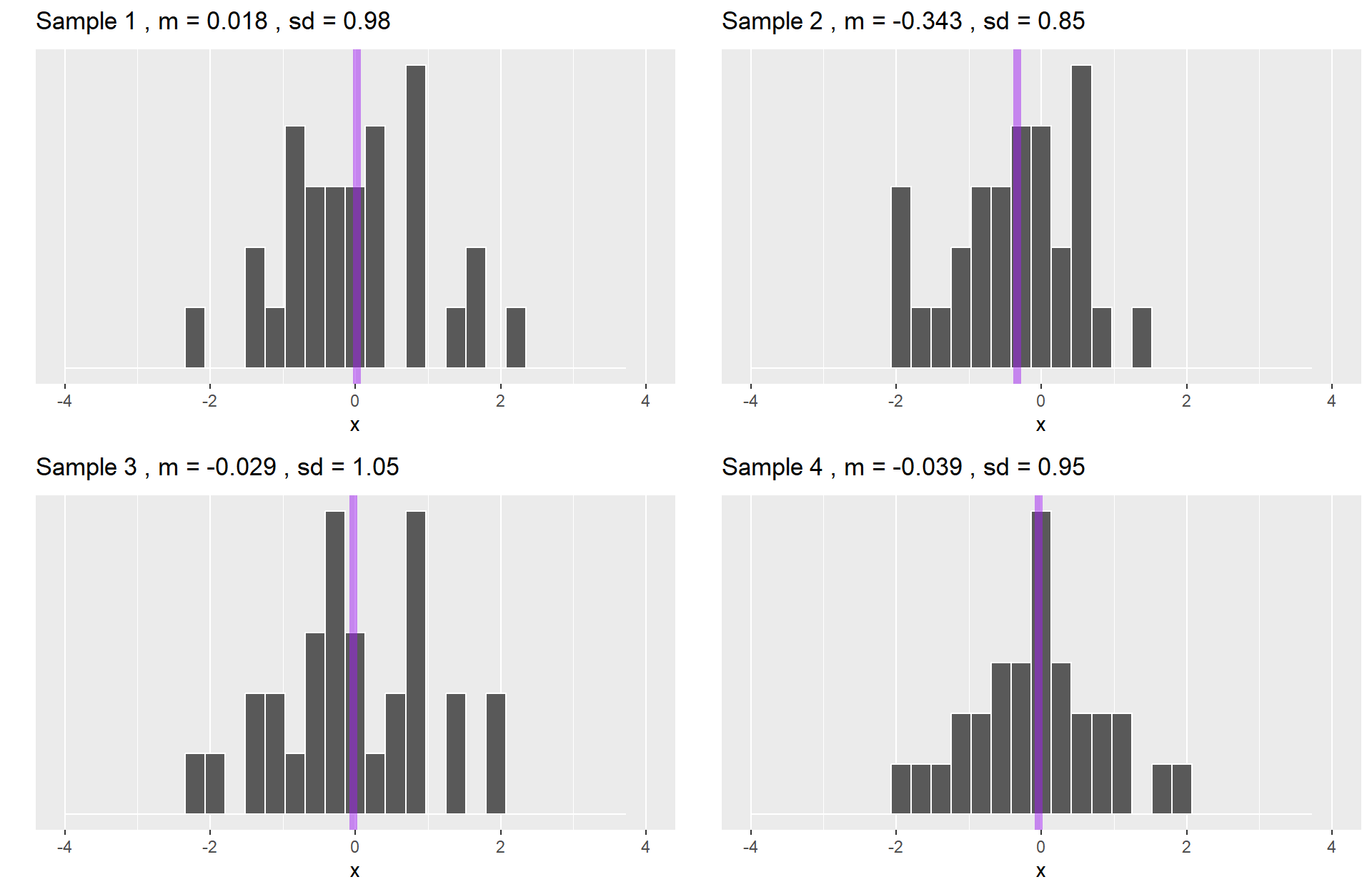
The statistics from a large number of samples also have a distribution: the sampling distribution.
By the Central Limit Theorem, this distribution will be normal as sample size increases.
Code
reps = 5000
means = rep(0, reps)
se = 1/sqrt(sample_size)
set.seed(101919)
for(i in 1:reps){
means[i] = mean(rnorm(n = sample_size))
}
data.frame(mean = means) %>%
ggplot(aes(x = mean)) +
geom_histogram(aes(y = ..density..),
fill = "purple",
color = "white") +
stat_function(fun = function(x) dnorm(x, mean = 0, sd = se), inherit.aes = F, size = 1.5) 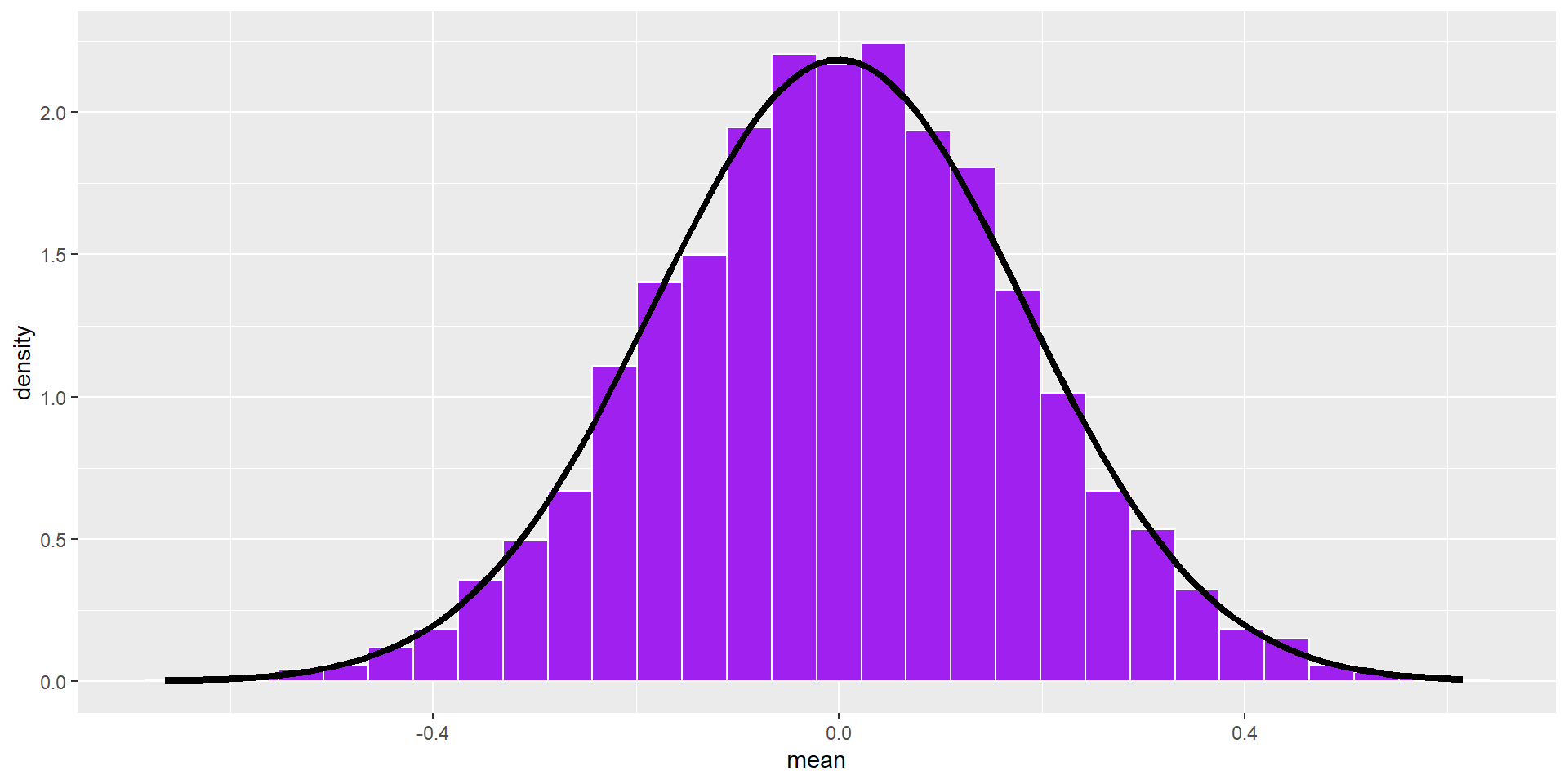
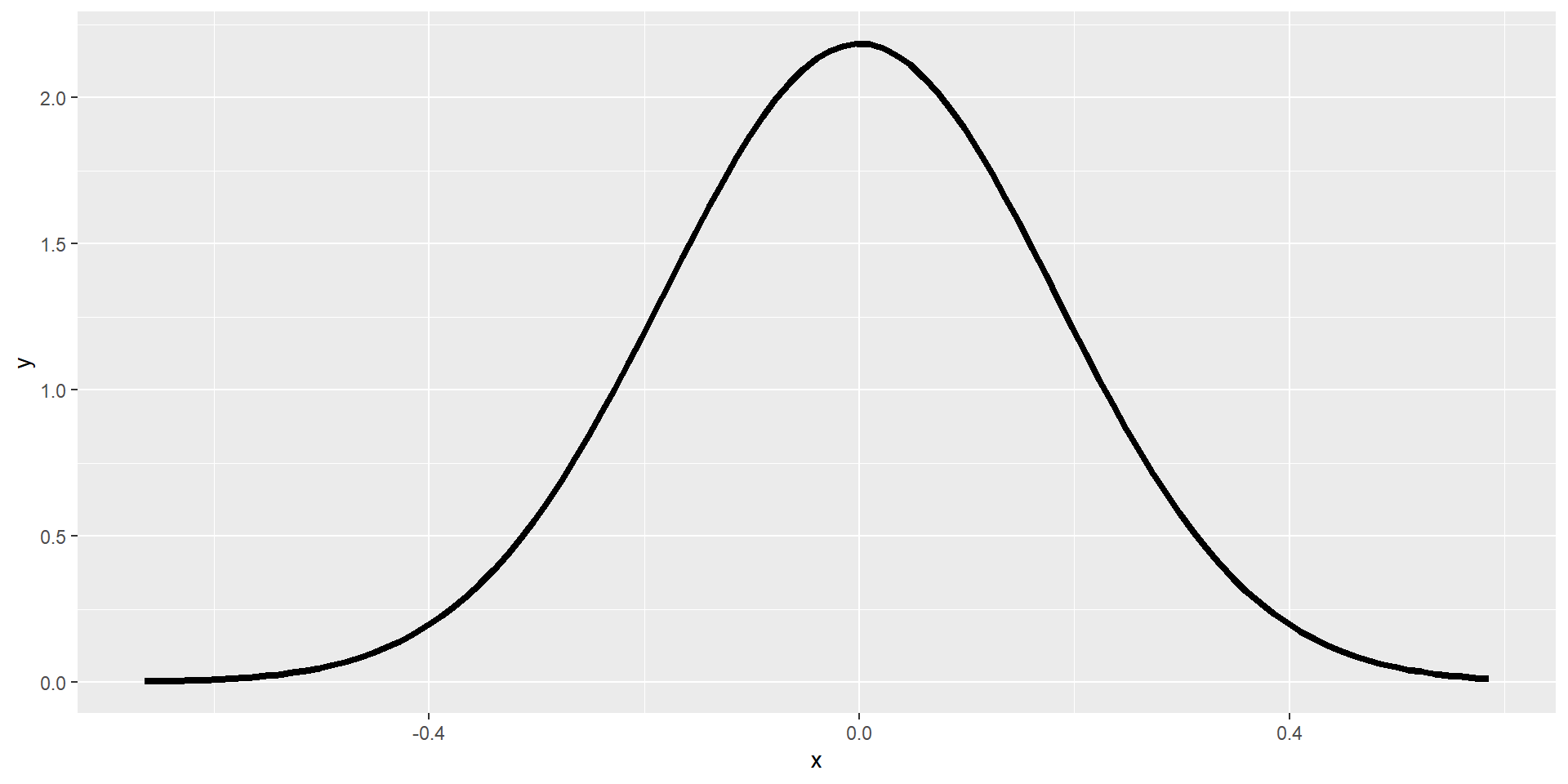
This distribution has a standard deviation, called the standard error of the mean. Its mean converges on \(\mu\).
We don’t actually have to take a large number of random samples to construct the sampling distribution. It is a theoretical result of the Central Limit Theorem. We just need an estimate of the population parameter, \(s\), which we can get from the sample.
Code
reps = 5000
means = rep(0, reps)
se = 1/sqrt(sample_size)
set.seed(101919)
for(i in 1:reps){
means[i] = mean(rnorm(n = sample_size))
}
data.frame(mean = means) %>%
ggplot(aes(x = mean)) +
geom_histogram(aes(y = ..density..),
fill = "purple",
color = "white") +
stat_function(fun = function(x) dnorm(x, mean = 0, sd = se), inherit.aes = F, size = 1.5) 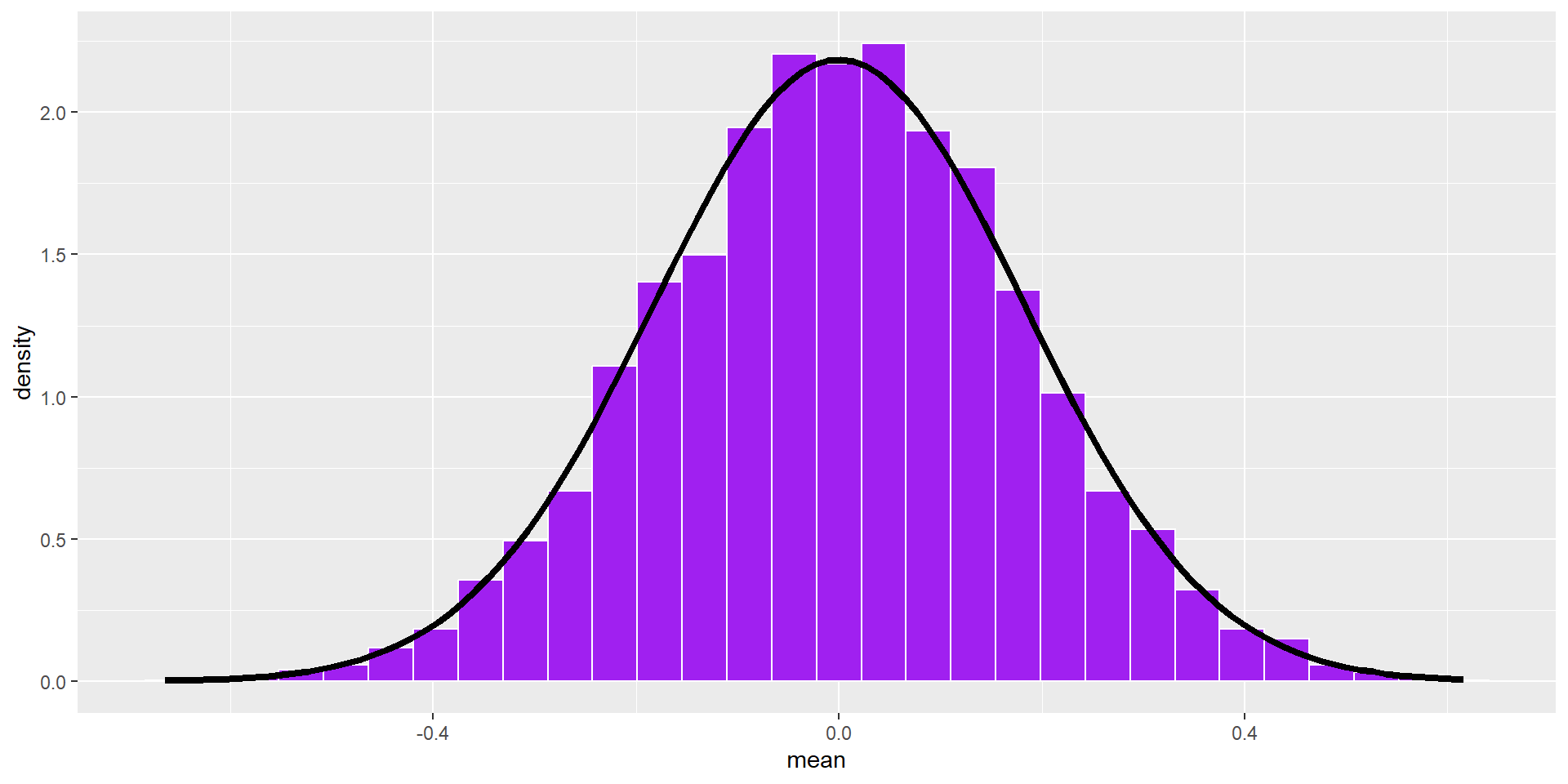
We don’t actually have to take a large number of random samples to construct the sampling distribution. It is a theoretical result of the Central Limit Theorem. We just need an estimate of the population parameter, \(s\), which we can get from the sample.
Remember the Empirical Rule (95%)
Code
ggplot(data.frame(x = seq(-4, 4)), aes(x)) +
stat_function(fun = function(x) dnorm(x)) +
stat_function(fun = function(x) dnorm(x),
xlim = c(-1.96, 1.96), geom = "area", fill = "purple", alpha = .3) +
geom_vline(aes(xintercept = 1.96), color = "purple")+
geom_vline(aes(xintercept = -1.96), color = "purple") +
geom_label(aes(x = 1.96, y = .3, label = "1.96"))+
geom_label(aes(x = -1.96, y = .3, label = "-1.96"))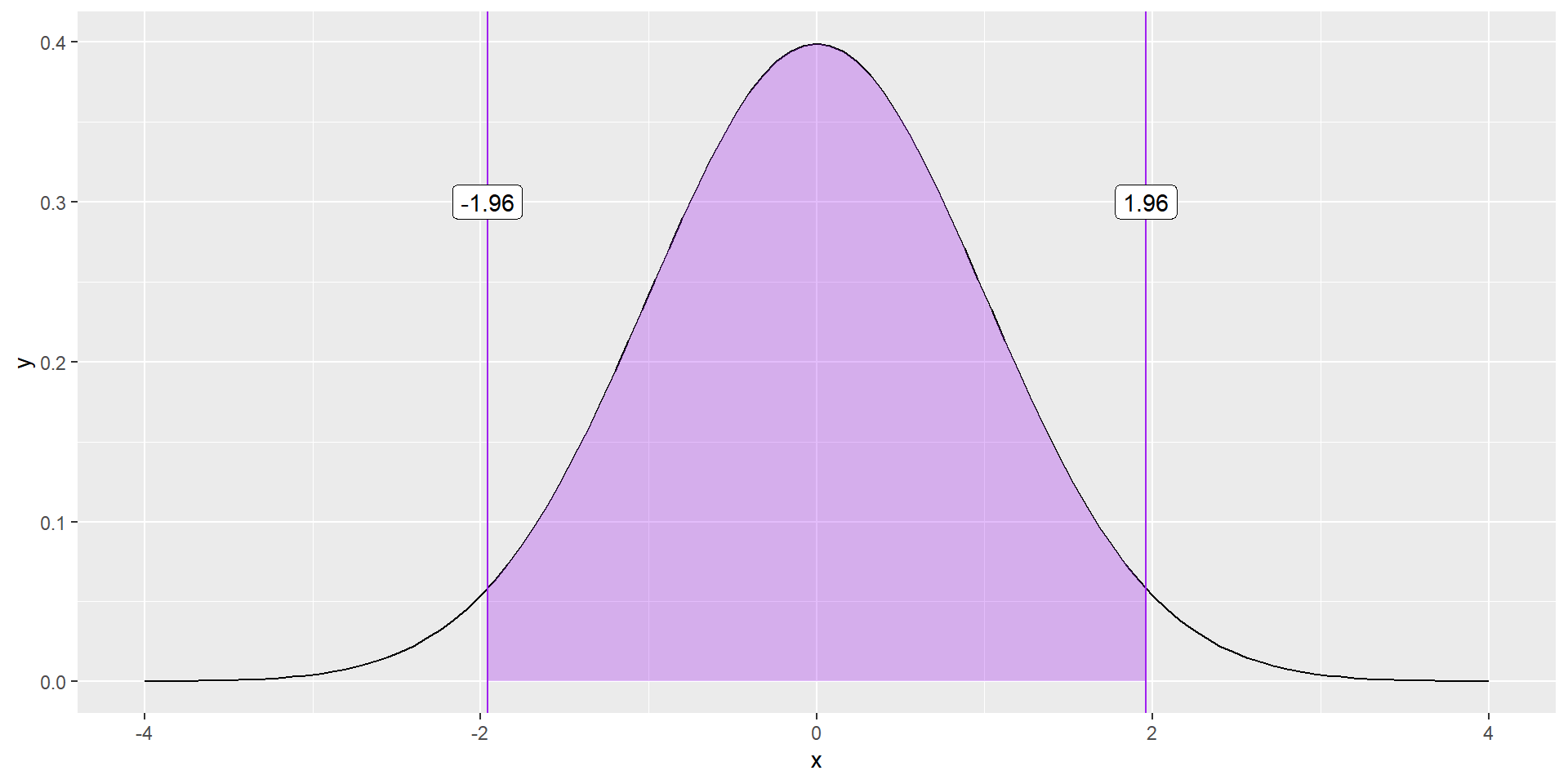
What if you didn’t know the value?
Code
ggplot(data.frame(x = seq(-4, 4)), aes(x)) +
stat_function(fun = function(x) dnorm(x)) +
stat_function(fun = function(x) dnorm(x),
xlim = c(-1.96, 1.96), geom = "area", fill = "purple", alpha = .3) +
geom_vline(aes(xintercept = 1.96), color = "purple")+
geom_vline(aes(xintercept = -1.96), color = "purple") +
geom_label(aes(x = 1.96, y = .3, label = "?"))+
geom_label(aes(x = -1.96, y = .3, label = "?"))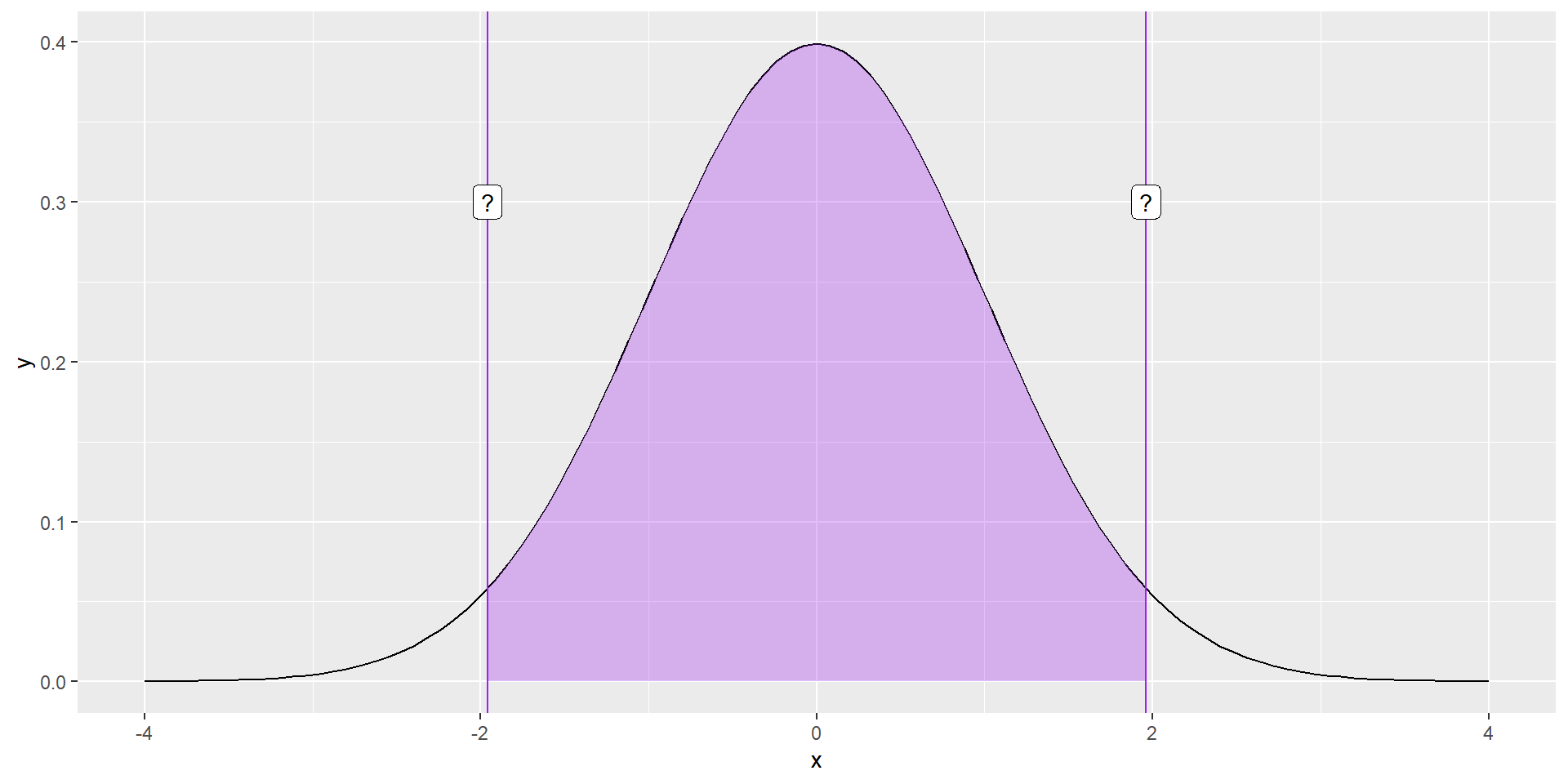
What if you didn’t know the value?
Code
ggplot(data.frame(x = seq(-4, 4)), aes(x)) +
stat_function(fun = function(x) dnorm(x)) +
stat_function(fun = function(x) dnorm(x),
xlim = c(-1.96, 1.96), geom = "area", fill = "purple", alpha = .3) +
stat_function(fun = function(x) dnorm(x),
xlim = c(-4, -1.96), geom = "area", fill = "green", alpha = .3) +
stat_function(fun = function(x) dnorm(x),
xlim = c(4, 1.96), geom = "area", fill = "green", alpha = .3) +
geom_vline(aes(xintercept = 1.96), color = "purple")+
geom_vline(aes(xintercept = -1.96), color = "purple") +
geom_label(aes(x = 1.96, y = .3, label = "?"))+
geom_label(aes(x = -1.96, y = .3, label = "?"))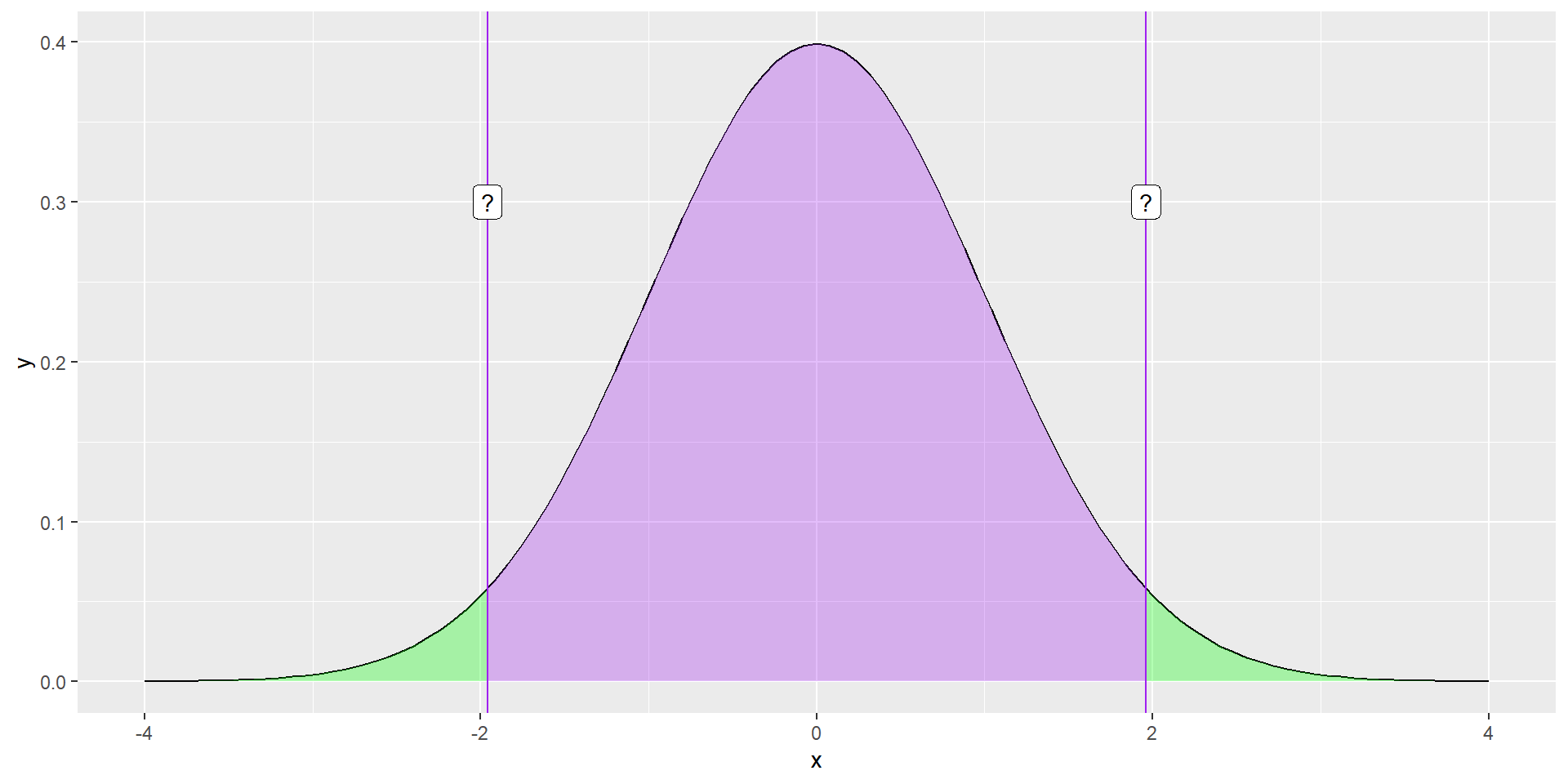
What if you didn’t know the value?
Code
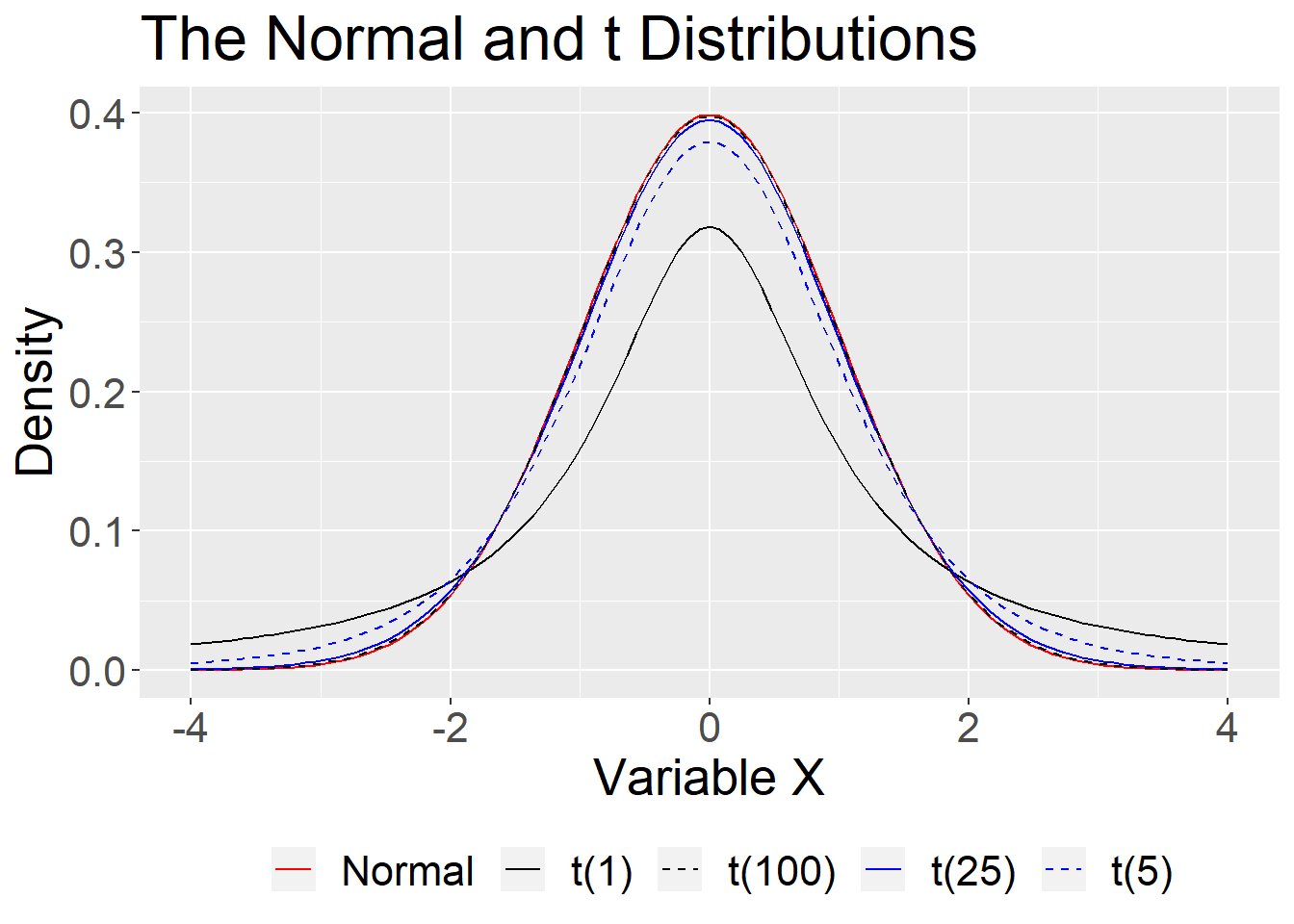
The normal distribution assumes we know the population mean and standard deviation. But we don’t. We only know the sample mean and standard deviation, and those have some uncertainty about them.
Code
ggplot(data.frame(x = seq(-4, 4)), aes(x)) +
stat_function(fun = function(x) dnorm(x),
aes(color = "Normal", linetype = "Normal")) +
stat_function(fun = function(x) dt(x, df = 1),
aes(color = "t(1)", linetype = "t(1)")) +
stat_function(fun = function(x) dt(x, df = 5),
aes(color = "t(5)", linetype = "t(5)")) +
stat_function(fun = function(x) dt(x, df = 25),
aes(color = "t(25)", linetype = "t(25)")) +
stat_function(fun = function(x) dt(x, df = 100),
aes(color = "t(100)", linetype = "t(100)")) +
scale_x_continuous("Variable X") +
scale_y_continuous("Density") +
scale_color_manual("",
values = c("red", "black", "black", "blue", "blue")) +
scale_linetype_manual("",
values = c("solid", "solid", "dashed", "solid", "dashed")) +
ggtitle("The Normal and t Distributions") +
theme(text = element_text(size=20),legend.position = "bottom")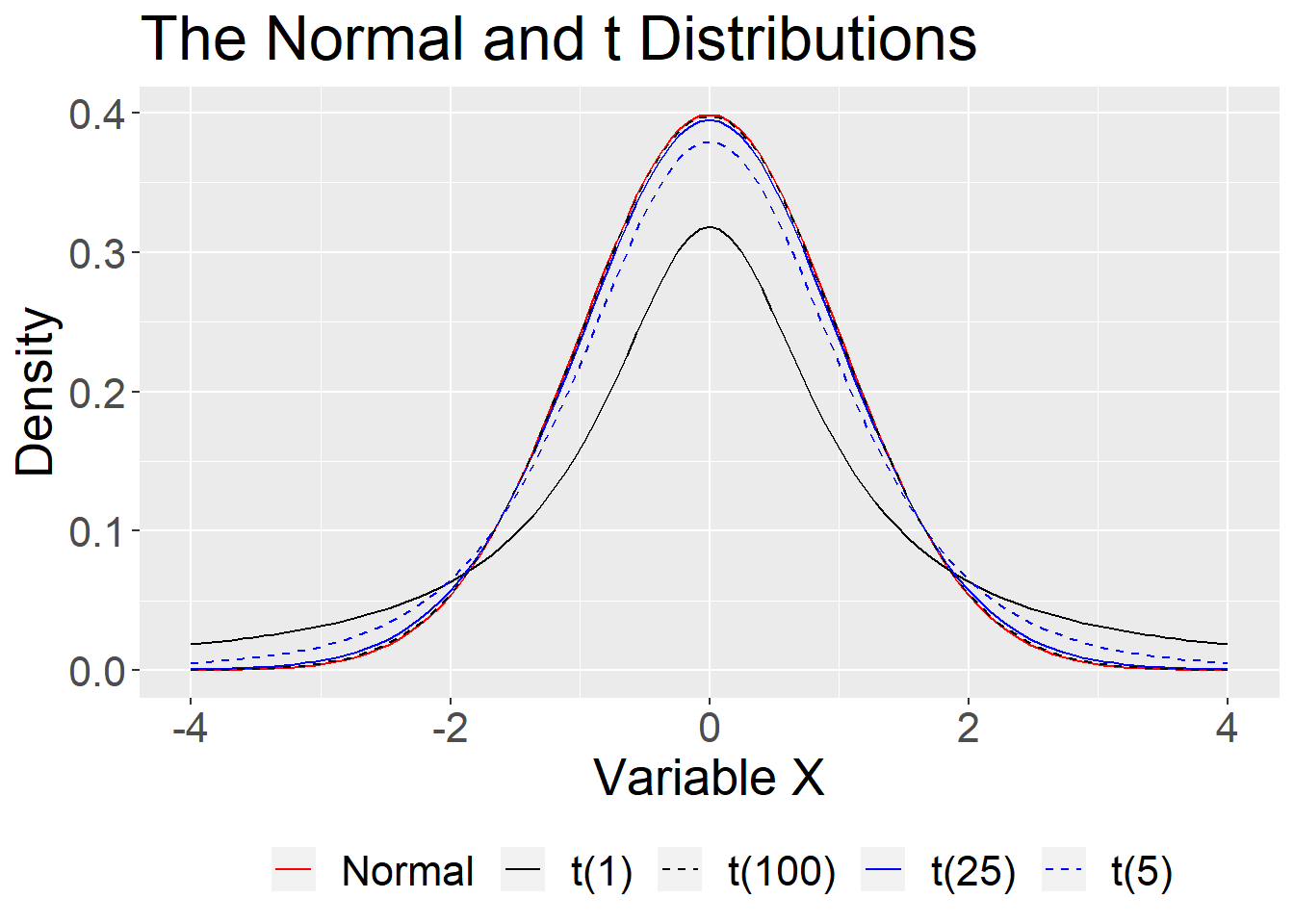
That uncertainty is reduced with large samples, so that the normal is “close enough.” In small samples, the \(t\) distribution provides a better approximation.
Code
ggplot(data.frame(x = seq(-4, 4)), aes(x)) +
stat_function(fun = function(x) dnorm(x),
aes(color = "Normal", linetype = "Normal")) +
stat_function(fun = function(x) dt(x, df = 1),
aes(color = "t(1)", linetype = "t(1)")) +
stat_function(fun = function(x) dt(x, df = 5),
aes(color = "t(5)", linetype = "t(5)")) +
stat_function(fun = function(x) dt(x, df = 25),
aes(color = "t(25)", linetype = "t(25)")) +
stat_function(fun = function(x) dt(x, df = 100),
aes(color = "t(100)", linetype = "t(100)")) +
scale_x_continuous("Variable X") +
scale_y_continuous("Density") +
scale_color_manual("",
values = c("red", "black", "black", "blue", "blue")) +
scale_linetype_manual("",
values = c("solid", "solid", "dashed", "solid", "dashed")) +
ggtitle("The Normal and t Distributions") +
theme(text = element_text(size=20),legend.position = "bottom")