Introduction to ANOVA
PSYC 640 - Fall 2023
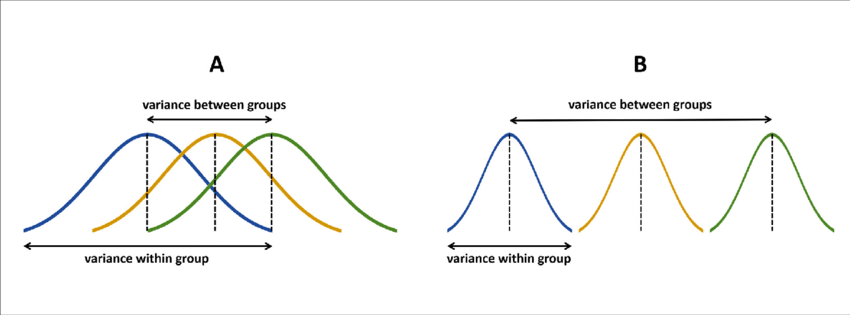
\(F = \frac{MS_{between}}{MS_{within}} = \frac{small}{large} < 1\)
\(F = \frac{MS_{between}}{MS_{within}} = \frac{large}{small} > 1\)
Sum of Squares
\[ SS_{total}=SS_{between}+SS_{within} \]
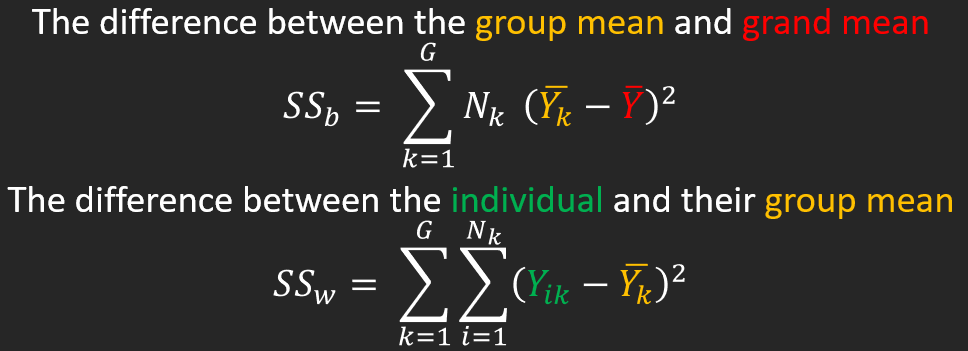
Example Data
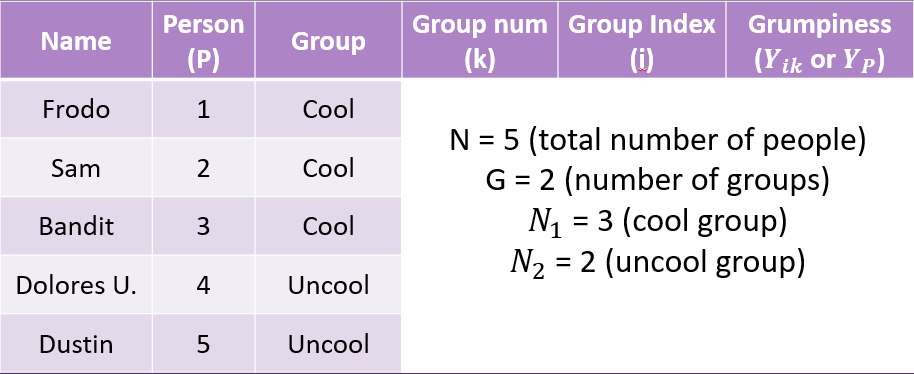
Example Data
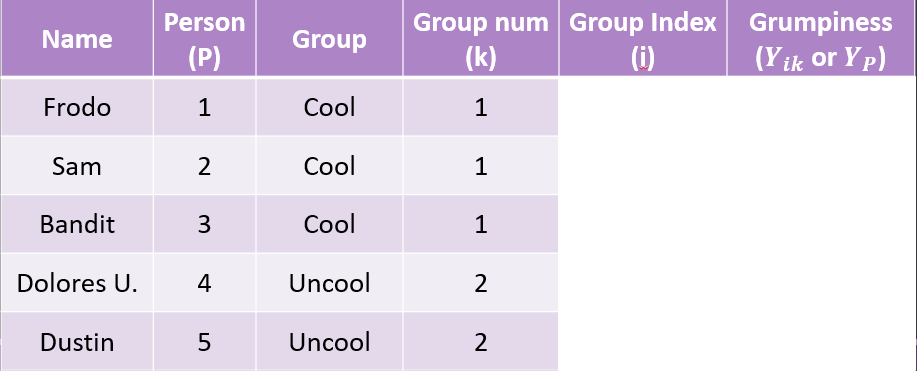
Example Data
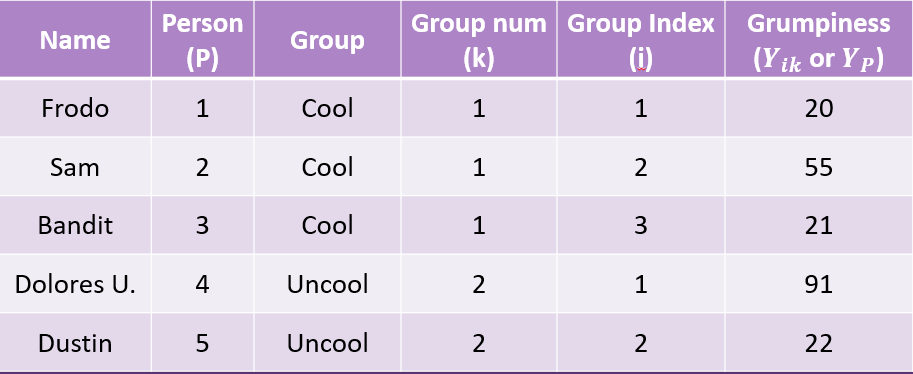
Example Data
Code
data.frame(F = c(0,8)) %>%
ggplot(aes(x = F)) +
stat_function(fun = function(x) df(x, df1 = 3, df2 = 196),
geom = "line") +
stat_function(fun = function(x) df(x, df1 = 3, df2 = 196),
geom = "area", xlim = c(2.65, 8), fill = "purple") +
geom_vline(aes(xintercept = 2.65), color = "purple") +
scale_y_continuous("Density") + scale_x_continuous("F statistic", breaks = NULL) +
theme_bw(base_size = 20)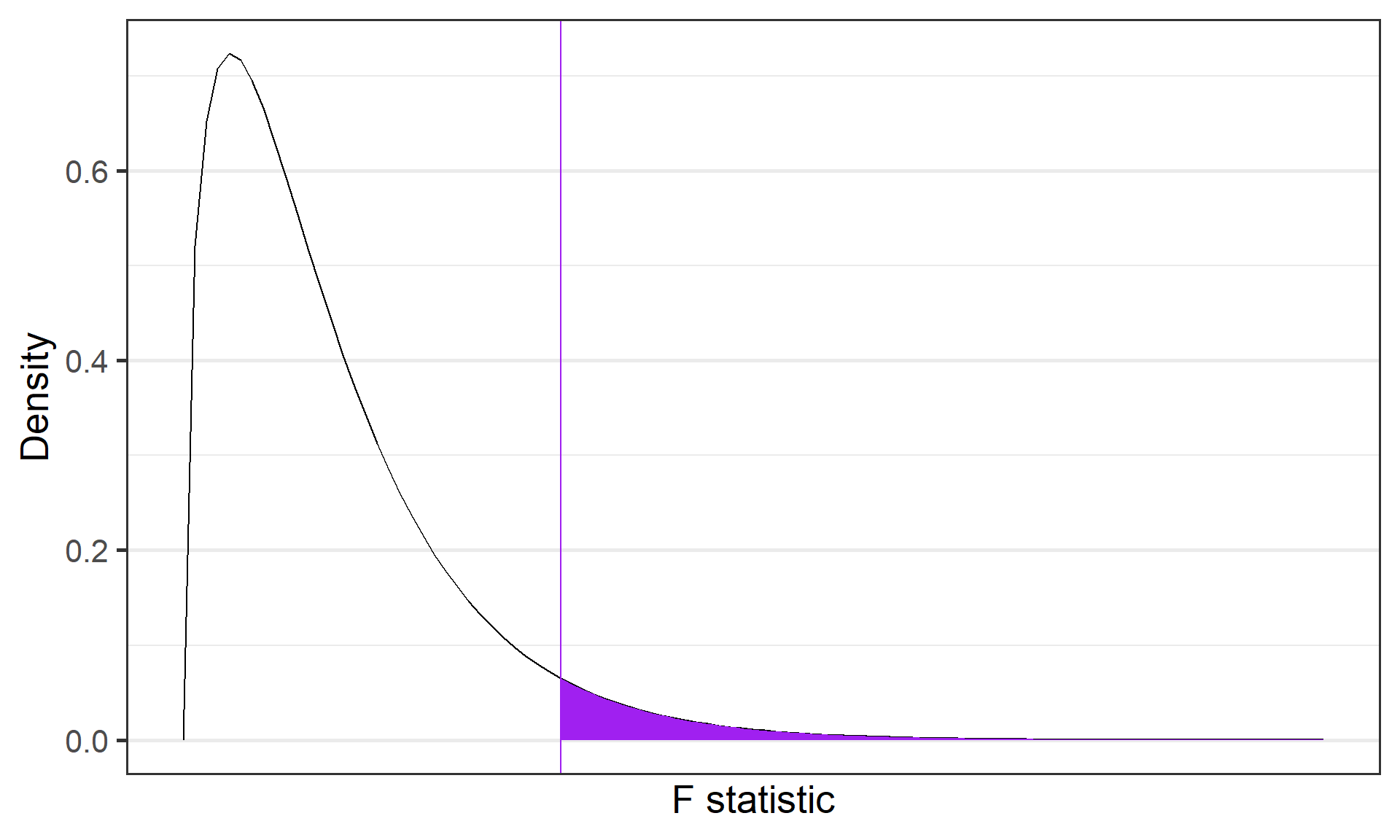
If data are normally distributed, then the variance is \(\chi^2\) distributed
\(F\)-distributions are one-tailed tests. Recall that we’re interested in how far away our test statistic from the null \((F = 1).\)
Code
data.frame(F = c(0,8)) %>%
ggplot(aes(x = F)) +
stat_function(fun = function(x) df(x, df1 = 3, df2 = 196),
geom = "line") +
stat_function(fun = function(x) df(x, df1 = 3, df2 = 196),
geom = "area", xlim = c(2.65, 8), fill = "purple") +
geom_vline(aes(xintercept = 2.65), color = "purple") +
geom_vline(aes(xintercept = 0.68), color = "red") +
annotate("text",
label = "F=0.68",
x = 1.1, y = 0.65, size = 8, color = "red") +
scale_y_continuous("Density") + scale_x_continuous("F statistic", breaks = NULL) +
theme_bw(base_size = 20)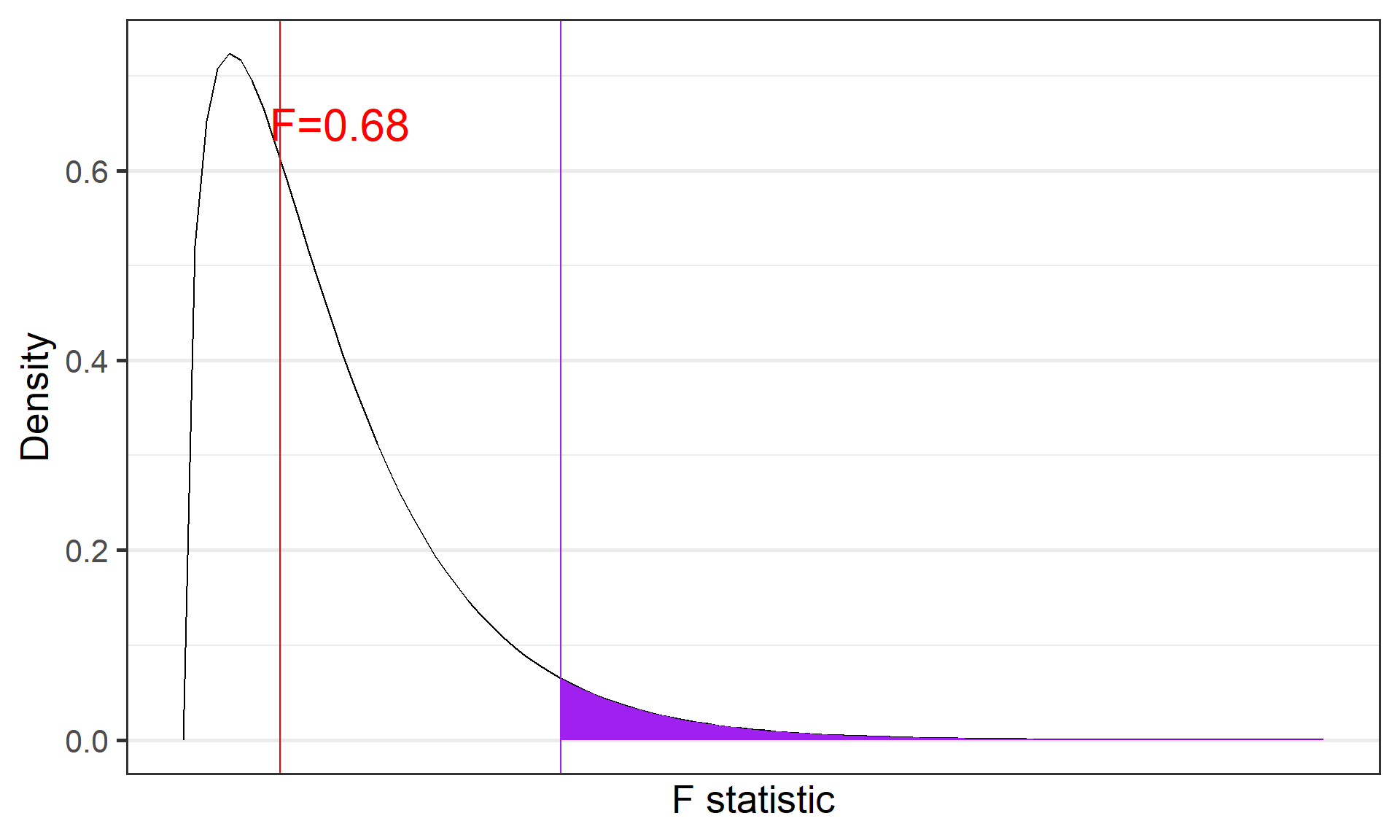
What can we conclude?