── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.1 ✔ tibble 3.2.1
✔ lubridate 1.9.4 ✔ tidyr 1.3.1
✔ purrr 1.0.4
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library(mice)
Attaching package: 'mice'
The following object is masked from 'package:stats':
filter
The following objects are masked from 'package:base':
cbind, rbind
library(broom)library(naniar) # For visualizing missingness
Missing Data Activity
Background
You are analyzing data from a study investigating how sleep quality and stress influence academic performance (GPA) in high school students.
Variables:
Sleep quality (actigraphy-based, continuous)
Stress level (self-report scale, continuous)
GPA (end-of-semester)
Three missing data scenarios were created:
MCAR: Some sleep trackers were lost at random.
MAR: Students with higher stress levels are less likely to wear the sleep tracker.
MNAR: Students with low GPA are more likely to skip GPA reporting.
Part 1: Explore the Missingness
Use naniar::gg_miss_var() to visualize which variables have missingness and how much.
Which variables are most affected in each scenario?
How would this affect your analysis if you used listwise deletion?
Part 2: Analyze Using Different Methods
For each dataset (MCAR, MAR, MNAR):
Fit a linear model (y ~ x1 + x2) using listwise deletion. Save the coefficients.
Use mean imputation to replace missing values in x1 and x2, then refit the model. Save results.
Use multiple imputation via mice, then pool and extract estimates. Save results.
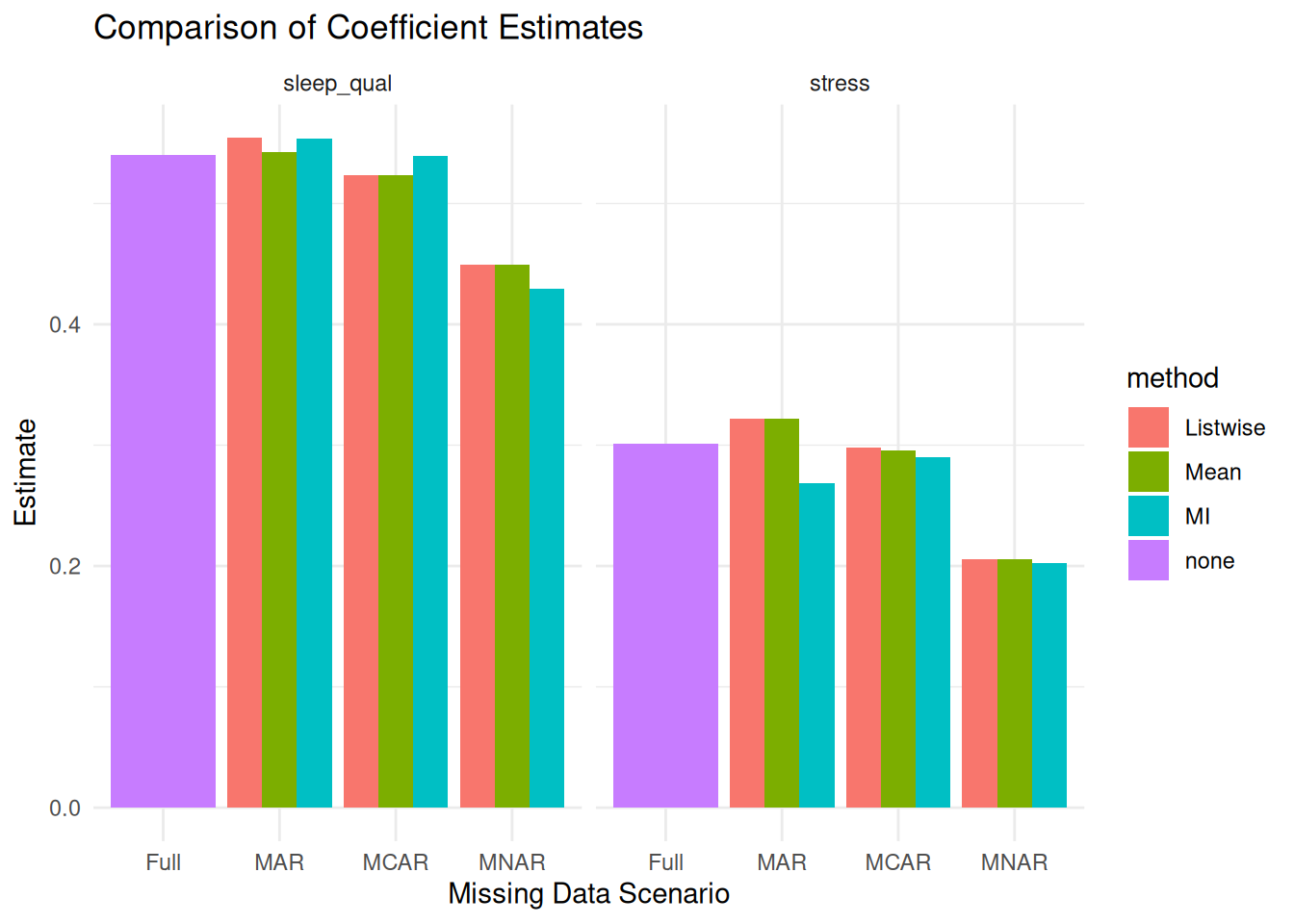
Compare your coefficients to the full (complete data) model. Which method is closest to the true values?
Part 3: Reflect and Discuss
Which method performed best for each scenario? Why?
Which scenario would you feel most confident analyzing and reporting? Least confident? Explain.
Ethical question:
MNAR Case: GPA missing due to low performance
Is it ethical to impute GPA?
Could it misrepresent actual student needs?
How would decisions based on imputed data affect interventions?
Simulate Dataset
You are conducting a study examining how sleep quality and stress levels predict academic performance in a sample of high school students.
# Function to fit a model and extract coefficientsfit_model <-function(data, formula = acad_perf ~ sleep_qual + stress) {lm(formula, data = data) %>%tidy()}
Some students accidentally lost their actigraphy devices, and their sleep data is missing. This happened randomly across the sample.
Implication: No systematic bias, but listwise deletion reduces power.
MAR (Missing at Random)
Students with higher stress were more likely to skip the sleep tracking part of the study because they felt overwhelmed. As a result, sleep data is more likely to be missing for students with high stress.
Implication: Bias is introduced unless the stress variable is used during imputation.
MNAR (Missing Not at Random)
Students who were failing classes were more likely to avoid reporting GPA due to embarrassment or fear of consequences. Thus, missingness in GPA is directly related to GPA itself.
Implication: Hardest case—there’s no observed variable to “explain” the missingness, and imputations are highly assumption-dependent.